10 การเรียนรู้ของเครื่อง เบื้องต้น
10.1 จากเครื่องจักรไอน้ำสู่ปัญญาประดิษฐ์: วิวัฒนาการอุตสาหกรรม
ก่อนที่จะทำความเข้าใจว่าการเรียนรู้ของเครื่อง (Machine Learning) คืออะไร เราจำเป็นต้องย้อนกลับไปพิจารณาโครงสร้างเชิงวิวัฒนาการของ “เครื่องมือ” ที่มนุษย์พัฒนาขึ้นในแต่ละยุคสมัย เพื่อให้เห็นภาพชัดเจนว่าเทคโนโลยีและระบบคิดถูกยกระดับขึ้นมาอย่างไร จนถึงจุดที่คอมพิวเตอร์สามารถเริ่ม “เรียนรู้และคิด” เองได้ในปัจจุบัน ดังรายละเอียดการเปรียบเทียบใน Table 10.1
| ยุคอุตสาหกรรม | หัวใจสำคัญของการขับเคลื่อน | บทบาทของข้อมูลและเทคโนโลยี |
|---|---|---|
| Industry 1.0 | Mechanical Production | การใช้พลังงานน้ำและ “ไอน้ำ” มาแทนที่แรงงานคนและสัตว์ |
| Industry 2.0 | Mass Production | การใช้ “ไฟฟ้า” และสายพานการผลิต (Assembly Line) เน้นการผลิตจำนวนมาก |
| Industry 3.0 | Automation | ยุคของ “คอมพิวเตอร์และอิเล็กทรอนิกส์” เริ่มใช้แขนกลและโปรแกรมควบคุม (PLC) |
| Industry 4.0 | Cyber-Physical Systems | ยุคของ “Internet of Things (IoT) และ Big Data” ที่ทุกระบบเชื่อมต่อเข้าหากัน [1] |
| Industry 5.0 | Personalization & Co-creation | “มนุษย์ทำงานร่วมกับปัญญาประดิษฐ์ (AI)” เน้นความยั่งยืน และการปรับแต่งตามความต้องการเฉพาะบุคคล |
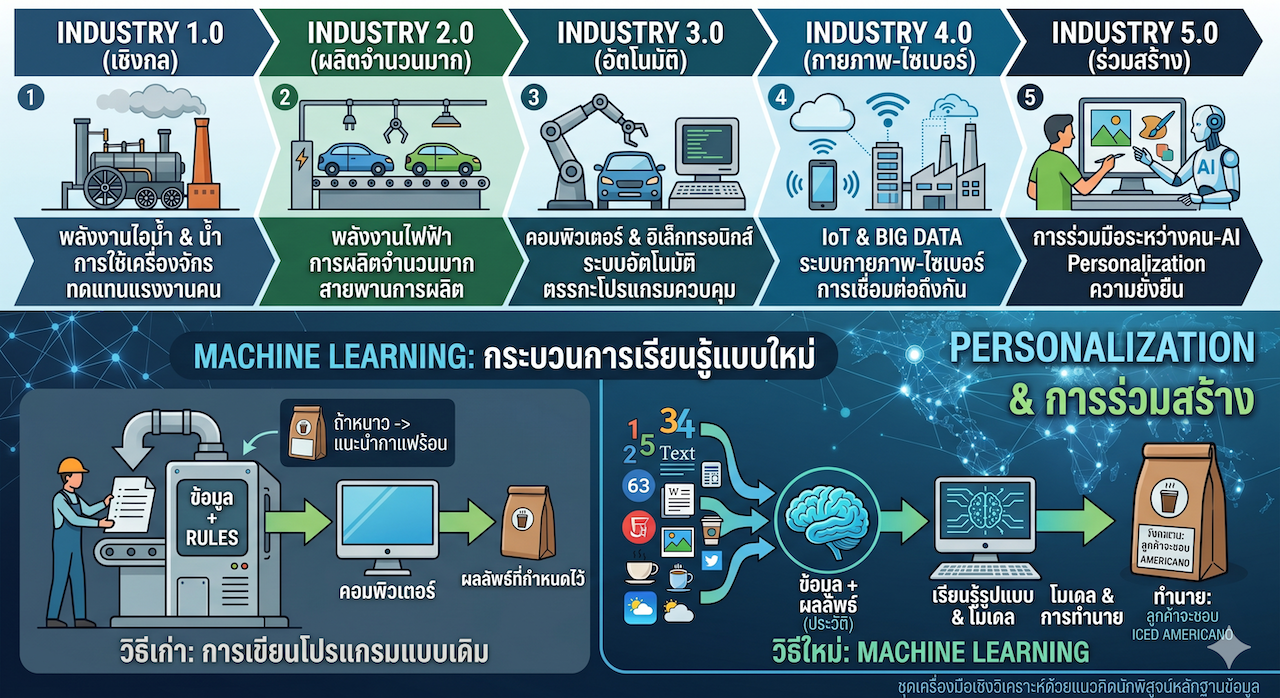
จาก Figure 10.1 ในยุค 1.0 - 2.0 เราใช้แรงงานคน ยุค 3.0 เราเริ่มเขียนกฎให้คอมพิวเตอร์ทำตาม (Traditional Programming) แต่ในยุค 4.0 และ 5.0 ข้อมูลมันมหาศาลเกินกว่าที่มนุษย์จะเขียนกฎไหว เราจึงต้องการก่ีเรียนรู้ของเครื่องมาเป็นตัวช่วยสำคัญ
10.2 การเรียนรู้ของเครื่อง: การเรียนรู้จากข้อมูลแทนการกำหนดกฎตายตัว
เมื่อเข้าสู่ยุค Industry 4.0 และ 5.0 ปริมาณข้อมูลที่เกิดขึ้นในระบบดิจิทัลเพิ่มขึ้นอย่างมหาศาล การใช้คอมพิวเตอร์เพื่อวิเคราะห์ข้อมูลจึงเปลี่ยนจากแนวทางเดิมที่อาศัยการกำหนดกฎอย่างชัดเจน ไปสู่แนวทางที่เปิดโอกาสให้ระบบสามารถเรียนรู้รูปแบบและความสัมพันธ์จากข้อมูลได้ด้วยตนเอง [2]
ยุคก่อน (Traditional Programming): เราป้อน ข้อมูล (Data) + กฎ (Rules) เช่น “ถ้าอุณหภูมิเกิน 30 องศา ให้เปิดแอร์” \(\rightarrow\) ผลลัพธ์ที่ได้คือ คำตอบ (Output)
ยุคการเรียนรู้ของเครื่อง: เราป้อน ข้อมูล (Data) + ผลลัพธ์ที่เคยเกิดขึ้น (Output/Answers) \(\rightarrow\) ให้ระบบไปหา “กฎหรือรูปแบบ” (Rules/Patterns) ออกมาเอง
10.3 วิวัฒนาการของการเรียนรู้: จากมนุษย์สู่การเรียนรู้ของเครื่อง
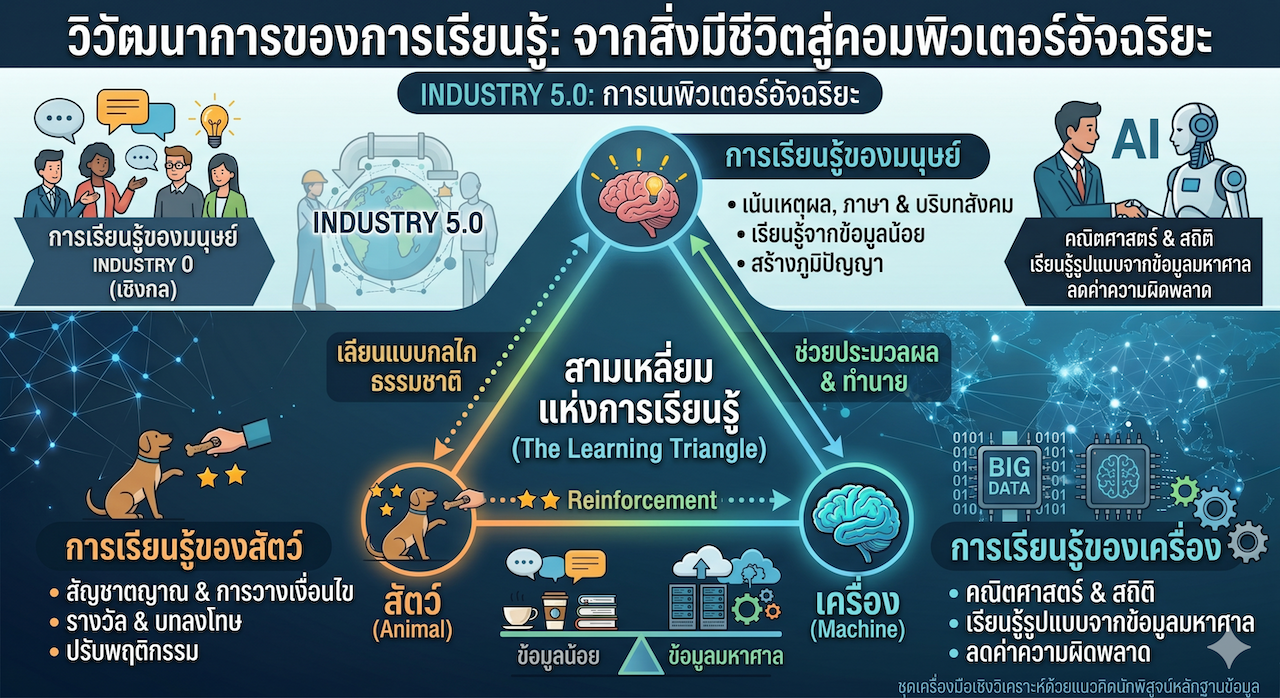
ตอนทำความเข้าใจการเรียนรู้ของเครื่อง จำเป็นต้องเริ่มจากแนวคิดพื้นฐานของ “การเรียนรู้” (Learning) ซึ่งหมายถึงกระบวนการเปลี่ยนประสบการณ์และข้อมูลที่ได้รับ ให้กลายเป็นความรู้ ทักษะ หรือความสามารถในการตัดสินใจที่ดีขึ้น
แนวคิดเรื่องการเรียนรู้มีพัฒนาการอย่างต่อเนื่อง ตั้งแต่การเรียนรู้ของมนุษย์และสิ่งมีชีวิต ไปจนถึงการพัฒนาระบบคอมพิวเตอร์ที่สามารถเรียนรู้รูปแบบจากข้อมูลได้ด้วยตนเอง
การเรียนรู้ของมนุษย์ (Human Learning)
กลไก: มนุษย์เรียนรู้ผ่าน เหตุผล (Logic), ภาษา (Language) และ บริบททางสังคม (Context)
ลักษณะเด่น: เราสามารถเรียนรู้จากข้อมูลจำนวนน้อยได้ (One-shot learning) เช่น เด็กเห็นเสือเพียงครั้งเดียวในรูปภาพ ก็สามารถจำแนกเสือตัวจริงในสวนสัตว์ได้ทันที เพราะมนุษย์มีโครงสร้างทางสมองที่ซับซ้อนและมีการสอนสั่ง
การเรียนรู้ของสัตว์ (Animal Learning)
กลไก: สัตว์เรียนรู้ผ่าน สัญชาตญาณ (Instinct) และ การวางเงื่อนไข (Conditioning)
ลักษณะเด่น: มักเป็นการเรียนรู้แบบ “รางวัลและบทลงโทษ” (Reward & Punishment) เช่น สุนัขเรียนรู้ที่จะขอมือเพื่อแลกกับขนม (Classical Conditioning)
จุดเชื่อมโยง: นี่คือรากฐานของการเรียนรู้แบบเสริมกำลัง (Reinforcement Learning) ในการเรียนรู้ของเครื่องที่ระบบจะเรียนรู้เพื่อเพิ่ม “คะแนนรางวัล” ให้ได้มากที่สุด
การเรียนรู้ของเครื่อง
กลไก: เรียนรู้ผ่านคณิตศาสตร์และสถิติ
ลักษณะเด่น: เครื่องจักรไม่มีสัญชาตญาณเหมือนสัตว์ และไม่มีบริบทเหมือนมนุษย์ แต่มันสามารถประมวลผล “ข้อมูลจำนวนมหาศาล” เพื่อหารูปแบบที่มนุษย์มองไม่เห็น
จุดต่าง: มนุษย์เรียนรู้เพื่อความอยู่รอดและสร้างสรรค์ แต่เครื่องจักรเรียนรู้เพื่อ “ลดค่าความผิดพลาด” (Minimize Error) ให้เหลือน้อยที่สุด [3]
การเรียนรู้ของเครื่องไม่ได้พยายามจะมา ‘แทนที่’ การเรียนรู้ของมนุษย์ แต่พยายาม ‘จำลอง’ วิธีการเรียนรู้ของสิ่งมีชีวิตมาใส่ในคอมพิวเตอร์ เพื่อให้มันช่วยเราประมวลผลในสิ่งที่สมองมนุษย์รับไม่ไหว เช่น การดูพฤติกรรมลูกค้าล้านคนพร้อมกัน นี่คือการรวมพลังระหว่างการเรียนรู้ของมนุษย์และการเรียนรู้ของเครื่อง ในยุคอุตสาหกรรม 5.0
10.4 การเรียนรู้ของเครื่อง: การเรียนรู้จากข้อมูลและประสบการณ์
ในการเขียนโปรแกรมแบบดั้งเดิม ผู้พัฒนาจะต้องกำหนดขั้นตอนและกฎการทำงานให้คอมพิวเตอร์อย่างชัดเจน เปรียบเสมือนการเขียน “คู่มือการทำงาน” ให้ระบบปฏิบัติตามทีละขั้นตอน
ในทางตรงกันข้าม การเรียนรู้ของเครื่องเป็นแนวทางที่เปิดโอกาสให้คอมพิวเตอร์เรียนรู้รูปแบบและความสัมพันธ์จากข้อมูลด้วยตนเอง เปรียบเสมือนการ “ส่งคอมพิวเตอร์ไปเรียนรู้จากประสบการณ์” เพื่อให้สามารถปรับปรุงการตัดสินใจหรือการคาดการณ์ได้อย่างต่อเนื่อง
10.4.1 การเปรียบเทียบเชิงโครงสร้าง
| กระบวนการ | การเขียนโปรแกรมแบบเดิม (Traditional) | การเรียนรู้ของเครื่อง (Machine Learning) |
|---|---|---|
| สิ่งที่ป้อนให้ระบบ | ข้อมูล + กฎ (Rules/Logic) | ข้อมูล + ผลลัพธ์ในอดีต (Answers/Labels) |
| หน้าที่ของคอมพิวเตอร์ | ทำตามคำสั่งอย่างเคร่งครัด | ค้นหา “รูปแบบ” (Patterns) ที่ซ่อนอยู่ |
| ผลลัพธ์ที่ได้ | คำตอบ (Output) | แบบจำลอง (Model) ที่ใช้ทำนายอนาคต |
3 ขั้นตอนหลักของการเรียนรู้ของเครื่อง
เพื่อให้เห็นภาพการทำงานจริง เราสามารถขยายความขั้นตอนที่อาจารย์สรุปไว้ได้ดังนี้
การป้อนข้อมูล (Data Feeding) ข้อมูลคือ “ครู” ของระบบ ยิ่งข้อมูลมีความหลากหลายและคุณภาพสูง ระบบยิ่งเรียนรู้ได้ดี
- ตัวอย่าง: หากต้องการให้ปัญญาประดิษฐ์ แยกแยะเมล็ดกาแฟที่ดีออกจากเมล็ดที่เสีย เราต้องป้อนรูปภาพเมล็ดกาแฟจำนวนมหาศาล พร้อมระบุว่ารูปไหนคือ “ดี” และรูปไหนคือ “เสีย”
การเรียนรู้รูปแบบ (Pattern Recognition) ขั้นตอนนี้คือหัวใจสำคัญ คอมพิวเตอร์จะใช้อัลกอริทึม (Algorithm) ทางสถิติและคณิตศาสตร์เพื่อมองหาความสัมพันธ์
- กลไก: ระบบจะสังเกตว่าเมล็ดที่ “เสีย” มักจะมีสีที่เข้มกว่าปกติ หรือมีรูปร่างที่บิดเบี้ยว โดยที่มนุษย์ไม่ต้องไปเขียน ชุดคำสั่ง (Code) บอกว่า “ถ้าสีเข้มกว่า x ให้ถือว่าเสีย” ระบบจะสรุปเกณฑ์นี้ขึ้นมาเอง
การใช้แบบจำลองทำนาย (Model Prediction) เมื่อระบบเรียนรู้จนได้ “แบบจำลอง” ที่แม่นยำแล้ว เราจะนำแบบจำลองนี้ไปใช้งานกับข้อมูลใหม่ที่ไม่เคยเห็นมาก่อน
- การประยุกต์ใช้: เมื่อมีเมล็ดกาแฟชุดใหม่ผ่านกล้อง ระบบจะใช้ “ประสบการณ์” ที่เรียนรู้มา ตัดสินใจได้ทันทีว่าเมล็ดนี้ควรถูกคัดออกหรือไม่? [4]
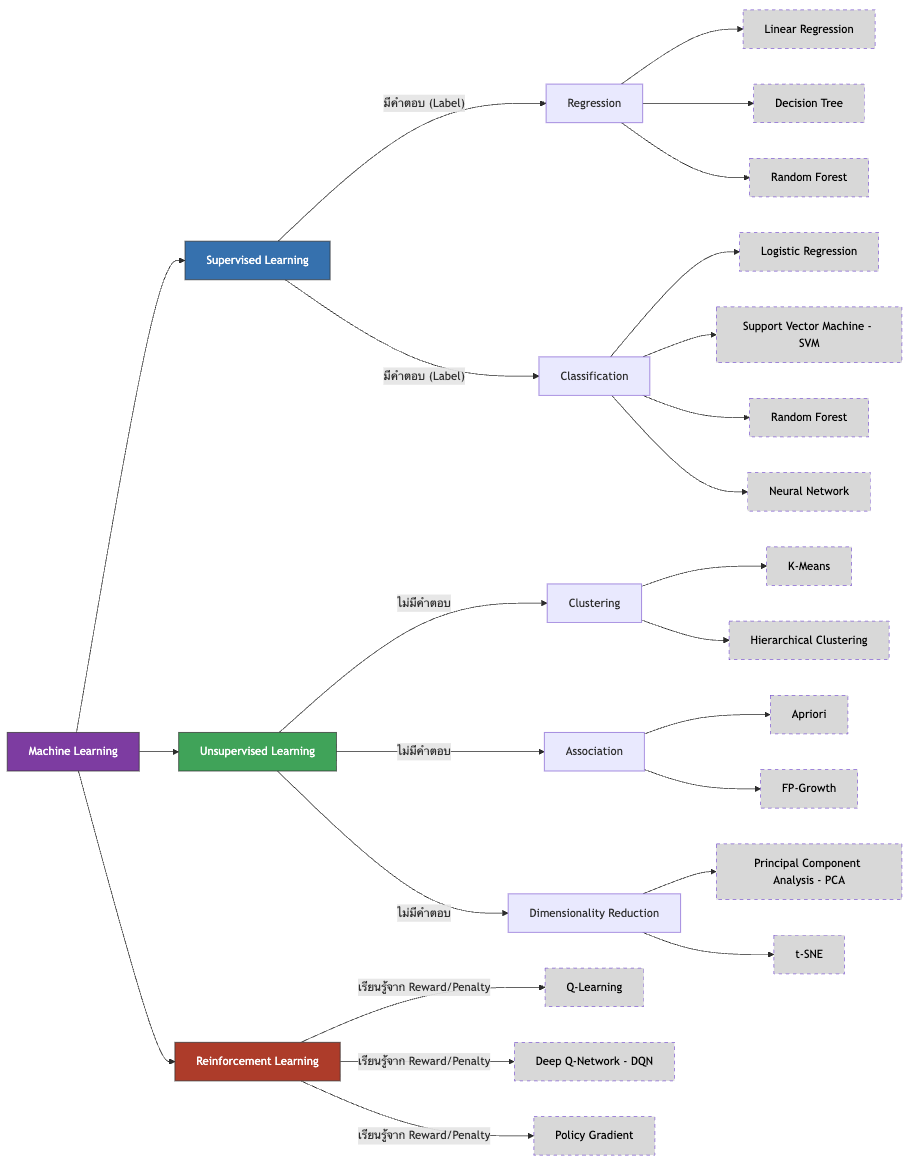
10.5 การจำแนกประเภทของการเรียนรู้ของเครื่อง (Taxonomy)
ในฐานะนักวิเคราะห์ข้อมูล เราต้องเลือก “วิธีการเรียนรู้” ให้เหมาะสมกับ “ลักษณะของหลักฐาน” ที่เรามี โดยแบ่งออกเป็น 3 สายหลักดังนี้
การเรียนรู้แบบมีผู้สอน (Supervised Learning) คือการเรียนรู้ที่มี “เฉลย” (Label) มาให้ในชุดข้อมูลฝึกสอน ระบบจะทำหน้าที่หาความสัมพันธ์ระหว่างปัจจัยนำเข้า (Input) กับคำตอบที่ถูกต้อง
การถดถอย (Regression): ทำนายค่าที่เป็นตัวเลขต่อเนื่อง เช่น ทำนายราคาคอนโดในเชียงใหม่จากพื้นที่และทำเล
การจำแนกประเภท (Classification): ทำนายกลุ่มหรือประเภท (ใช่/ไม่ใช่, A/B/C) เช่น ทำนายว่าลูกค้า Chiang Mai Brew คนนี้จะเลิกใช้บริการ (Churn) หรือไม่ จากประวัติการซื้อ [5]
การเรียนรู้แบบไม่มีผู้สอน (Unsupervised Learning) คือการเรียนรู้ที่ “ไม่มีเฉลย” มาให้ ระบบต้องทำการสำรวจและหาโครงสร้างหรือรูปแบบที่ซ่อนอยู่ (Hidden Patterns) ด้วยตัวเอง
การจัดกลุ่ม(Clustering): แบ่งข้อมูลที่มีลักษณะคล้ายกันให้อยู่กลุ่มเดียวกัน เช่น การจัดกลุ่มลูกค้า (Customer Segmentation) เพื่อแบ่งกลุ่มลูกค้าที่ชอบมานั่งทำงาน กับกลุ่มลูกค้าที่มาซื้อแบบรวดเร็ว (Grab-and-Go) เพื่อวางแผนโปรโมชั่นที่ต่างกัน [2]
การหาความสัมพันธ์ (Association): หาว่าสิ่งใดมักเกิดขึ้นพร้อมกัน เช่น ลูกค้าที่ซื้อครัวซองต์ มักจะซื้อลาเต้ร้อนคู่กันเสมอ (Market Basket Analysis)
การเรียนรู้แบบเสริมกำลัง(Reinforcement Learning) คือการเรียนรู้ผ่าน “การลองผิดลองถูก” ในสภาพแวดล้อมจำลอง โดยมีระบบให้รางวัล (Reward) เมื่อทำถูกต้อง และลงโทษ (Penalty) เมื่อทำผิด เช่น ระบบปัญญาประดิษฐ์ในรถยนต์ไร้คนขับที่เรียนรู้การเลี้ยวหลบสิ่งกีดขวาง หรือปัญญาประดิษฐ์ในเกมหมากรุกที่พยายามเดินแต้มเพื่อให้ได้ชัยชนะ (ซึ่งได้รางวัลสูงสุด)
เพื่อให้เห็นภาพรวมของเครื่องมือที่เราจะนำไปใช้ในการวิเคราะห์ข้อมูล เราสามารถจำแนกประเภทของการเรียนรู้ของเครื่อง ออกตามลักษณะของ “ข้อมูลนำเข้า” และ “เป้าหมายในการวิเคราะห์” ได้ดังแสดงใน Figure 10.2
เพื่อให้เห็นภาพรวมของเครื่องมือที่เราจะนำไปใช้ในการวิเคราะห์ข้อมูล เราสามารถจำแนกประเภทของ Machine Learning ออกตามลักษณะของ “ข้อมูลนำเข้า” และ “เป้าหมายในการวิเคราะห์” ได้ดังแสดงใน Figure 10.3
10.6 บทสรุปและก้าวต่อไป: จากทฤษฎีสู่การลงมือทำจริง
ในบทเรียนนี้ เราได้ปูพื้นฐานให้เห็นว่าการเรียนรู้ของเครื่อง คือเครื่องยนต์สำคัญที่ขับเคลื่อนอุตสาหกรรมในยุค 5.0 ผ่านการเรียนรู้จากข้อมูลมหาศาลเพื่อสร้างแต้มต่อทางธุรกิจ [6] อย่างไรก็ตาม ความเข้าใจในเชิงหลักการเป็นเพียงกุญแจดอกแรกเท่านั้น
ในบทถัดไป เราจะลงลึกถึงรายละเอียดของแบบจำลองที่สำคัญในกลุ่มการเรียนรู้แบบมีผู้สอน เช่น สมการถดถอยเชิงเส้นสำหรับการพยากรณ์ตัวเลข และ ต้นไม้การตัดสินใจ (Decision Tree) สำหรับการจำแนกประเภท รวมถึงกลุ่มการเรียนรู้แบบไม่มีผู้สอน เช่น K-Means สำหรับการจัดกลุ่มลูกค้า ซึ่งเป็นอาวุธหลักที่นักวิเคราะห์ข้อมูลต้องมีติดตัวไว้
นอกจากนี้ เราจะก้าวข้ามขีดจำกัดของสมการบนหน้ากระดาษ ไปสู่การฝึกปฏิบัติจริงด้วยโปรแกรม Orange Data Mining ซึ่งเป็นเครื่องมือแบบ Visual Programming ที่ทรงพลัง นักศึกษาจะได้ทดลองลากวาง (Drag-and-Drop) เพื่อสร้าง Data Workflow ตั้งแต่การนำเข้าข้อมูล การทำ Pre-processing ไปจนถึงการวัดประสิทธิภาพของแบบจำลองด้วยตัวเอง [7]
10.7 แบบฝึกหัดท้ายบท
ความแตกต่างที่สำคัญระหว่างการเขียนโปรแกรมแบบเดิมกับ การเรียนรู็ของเครื่องคืออะไร?
ในยุค Industry 5.0 มนุษย์และปัญญาประดิษฐ์ มีความสัมพันธ์กันอย่างไร?
จงยกตัวอย่างข้อมูลที่เป็น “Label” ในงานทำนายยอดขายร้านกาแฟ
หากต้องการแบ่งกลุ่มลูกค้าตามความชอบโดยไม่มีข้อมูลกลุ่มเดิมอยู่เลย ควรใช้แบบจำลองการรู้ของเครื่องประเภทใด?
ขั้นตอนแบบจำลองใน Data Science Workflow ทำหน้าที่อะไร?
การเรียนรู้ของเครื่องใช้หลักการใดในการลดความคลาดเคลื่อน?
“การคัดแยกอีเมลขยะ” จัดเป็นงานประเภทการพยากรณ์ (Regression) หรือการจำแนก (Classification)? เพราะเหตุใด? [8]
“การหาว่าสินค้าใดมักถูกซื้อคู่กัน” จัดเป็นการเรียนรู้ของเครื่องประเภทใด?
จงยกตัวอย่างสถานการณ์ที่เหมาะกับการใช้การเรียนรู้แบบเสริมกำลัง (Reinforcement Learning)
ประโยชน์ของการใช้วิธีการลดจำนวนมิติข้อมูล (Dimensionality Reduction (เช่น PCA)) คืออะไร?