| TV | Radio | Newspaper | Sales |
|---|---|---|---|
| 86.27326 | 11.93630 | 98.60543 | 12.18448 |
| 236.49154 | 48.11795 | 13.70675 | 25.98697 |
| 122.69308 | 30.06829 | 90.53096 | 16.94775 |
| 264.90522 | 25.75149 | 57.63018 | 22.63780 |
| 282.14019 | 20.12867 | 39.54489 | 23.37532 |
| 13.66695 | 44.01233 | 44.98025 | 16.47655 |
11 การเรียนรู้แบบมีผู้สอนสำหรับวิทยาการข้อมูล
11.1 แนวคิดของการเรียนรู้ที่มีผู้สอน
การเรียนรู้แบบมีผู้สอนคือหัวใจสำคัญของการสร้างแบบจำลองเพื่อการทำนาย โดยมีหลักการง่ายๆ คือการสอนให้คอมพิวเตอร์เรียนรู้จาก “ประสบการณ์ในอดีตที่มีการระบุผลลัพธ์ไว้ชัดเจน” เปรียบเสมือนนักศึกษาที่ฝึกทำโจทย์ข้อสอบเก่าโดยมี “เฉลย” อยู่ในมือ เพื่อให้เข้าใจว่าโจทย์ลักษณะนี้ ควรจะได้คำตอบแบบใด [1]
11.1.1 ตัวอย่างการประยุกต์ใช้ในทางธุรกิจ
เพื่อให้เห็นภาพการนำไปใช้จริงในหน้างานของนักวิเคราะห์ข้อมูล ลองพิจารณาสถานการณ์ต่อไปนี้
11.1.2 เจาะลึกกรณีศึกษา: พยากรณ์การลาออกของลูกค้า (Customer Churn)
ในสถานการณ์จริง นักวิเคราะห์ข้อมูลไม่ได้เริ่มที่การเลือกแบบจำลอง แต่เริ่มจากการทำความเข้าใจ “ปัญหา” และ “หลักฐาน” ที่มีในมือดังนี้
Importantปัญหาทางธุรกิจ (The Problem)
ร้าน Chiang Mai Brew เริ่มสังเกตเห็นว่าลูกค้าประจำบางกลุ่มหายหน้าไป และกว่าจะรู้ตัวว่าลูกค้าเลิกใช้บริการ (Churn) ก็สายเกินกว่าจะดึงตัวกลับมาได้แล้ว การจะให้พนักงานคอยจำพฤติกรรมลูกค้าหลายพันคนด้วย “ความจำมนุษย์” นั้นเป็นไปไม่ได้ ร้านจึงสูญเสียรายได้และต้องจ่ายงบโฆษณาหาลูกค้าใหม่ที่แพงกว่าการรักษาลูกค้าเก่าถึง 5 เท่า!
11.1.3 ข้อมูลที่ต้องการ
ในการวิดคราะห์ปัญหานี้ เรามีฐานข้อมูลการเป็นสมาชิก (Membership System) ย้อนหลัง 1 ปี ซึ่งมีข้อมูลตาม Table 11.1 ดังนี้
| ชื่อตัวแปร (X) | ความหมาย | รูปแบบข้อมูล |
|---|---|---|
Recency |
จำนวนวันนับจากการซื้อครั้งล่าสุดจนถึงปัจจุบัน | ตัวเลข (วัน) |
Frequency |
จำนวนครั้งที่ลูกค้ามาใช้บริการในรอบ 1 ปี | ตัวเลข (ครั้ง) |
Monetary |
ยอดรวมการใช้จ่ายทั้งหมดของลูกค้าคนนั้น | ตัวเลข (บาท) |
Membership_Age |
ระยะเวลาที่เป็นสมาชิก (กี่เดือน) | ตัวเลข (เดือน) |
| Status (Y) | สถานะปัจจุบัน (เลิกใช้บริการ / ยังใช้อยู่) | หมวดหมู่ (Churn / Active) |
ก่อนที่คอมพิวเตอร์จะเรียนรู้ได้ เราต้องเปลี่ยน ‘ความรู้สึก’ ให้เป็น ‘พยานหลักฐาน’ (Features) เสียก่อน อย่างเช่น คำว่า ‘มาบ่อยแค่ไหน’ ต้องถูกแปลงเป็นตัวเลข Frequency หรือ ‘หายหน้าไปนานหรือยัง’ ต้องแปลงเป็น Recency ข้อมูลเหล่านี้แหละที่จะถูกส่งเข้าเครื่องยนต์การเรียนรู้แบบมีผู้สอนเพื่อหา Pattern ว่า คนที่หายไปนานเกินกี่วัน (X) ถึงจะมีโอกาสเลิกใช้บริการสูง (Y)
11.1.4 เจาะลึกกรณีศึกษา: พยากรณ์ยอดขายรายวัน (Sales Forecasting)
ในงานวิเคราะห์เชิงปริมาณ การคาดการณ์ “ตัวเลข” ได้อย่างแม่นยำคือหัวใจของการลดต้นทุนและเพิ่มประสิทธิภาพ (Optimization)ในการทำกำไร
Importantปัญหาทางธุรกิจ
ร้าน Chiang Mai Brew มักประสบปัญหา “ของขาด” ในวันที่ลูกค้าเยอะ และ “ของเหลือ” ในวันที่เงียบเหงา ซึ่งส่งผลต่อต้นทุนวัตถุดิบสด (Waste) และการจัดตารางกะพนักงานที่ไม่สมดุลกับปริมาณลูกค้า การจะใช้เพียง “ความรู้สึก” ของผู้จัดการร้านในการสั่งของนั้นมีความคลาดเคลื่อนสูง เราจึงต้องการแบบจำลองที่ช่วยบอกได้ว่า “พรุ่งนี้ยอดขายจะเป็นกี่บาท?” [2]
11.1.5 ข้อมูลที่ต้องการ
ในการสร้างแบบจำลองพยากรณ์นี้ เราได้รวบรวมข้อมูลรายวันย้อนหลัง (Daily Logs) เพื่อหาความสัมพันธ์ของตัวแปรต่างๆ ดังนี้:
| ชื่อตัวแปร (X) | ความหมาย | รูปแบบข้อมูล |
|---|---|---|
FB_Ad_Spend |
งบประมาณโฆษณาที่ยิงผ่าน Facebook ในวันนั้น | ตัวเลข (บาท) |
Is_Holiday |
วันนั้นเป็นวันหยุดหรือวันนักขัตฤกษ์หรือไม่ | ตัวแปรหุ่น (0 = ไม่ใช่, 1 = ใช่) |
Avg_Temp |
อุณหภูมิเฉลี่ยในวันนั้น (เพื่อดูผลของอากาศต่อยอดขายเครื่องดื่ม) | ตัวเลข (องศาเซลเซียส) |
Promotion_Active |
มีการจัดโปรโมชั่นพิเศษหรือไม่ | ตัวแปรหุ่น (0 = ไม่มี, 1 = มี) |
| Daily_Sales (Y) | ยอดขายรวมสุทธิประจำวัน | ตัวเลขต่อเนื่อง (บาท) |
คือจุดเชื่อมต่อที่สำคัญมากระหว่าง ‘เศรษฐมิติ’ และ ‘วิทยาศาสตร์ข้อมูล’ ในทางสถิติเราอาจจะมองหาค่าสัมประสิทธิ์ (\(\beta\)) เพื่อดูผลกระทบของงบโฆษณา แต่ในแง่ของของการเรียนรู้ของเครื่อง เป้าหมายของเราคือการสร้างฟังก์ชันที่ทำนายยอดขาย (\(Y\)) ให้ใกล้เคียงความจริงมากที่สุด เพื่อที่เราจะได้สั่งเมล็ดกาแฟและนมสดมาสต็อกไว้ได้อย่างแม่นยำ ไม่เหลือทิ้งให้เป็นภาระต้นทุนนั่นเอง
11.2 การวิเคราะห์การถดถอย
คือการใช้แบบจำลองการเรียนรู้ของ เพื่อทำนายผลลัพธ์ที่เป็น “ค่าตัวเลขต่อเนื่อง” (Continuous Values) ซึ่งคำตอบที่ได้จะมีค่าเป็นเท่าใดก็ได้ภายในช่วงที่เหมาะสม ไม่ใช่การแบ่งกลุ่ม
11.2.1 แบบจำลอง: การถดถอยเชิงเส้นอย่างง่าย (Simple Linear Regression)
เป็นจุดเริ่มต้นที่สำคัญที่สุด โดยเราตั้งสมมติฐานว่า “ตัวแปรอิสระเพียงตัวเดียว (\(X\))” มีความสัมพันธ์เชิงเส้นกับ “ตัวแปรตาม (\(Y\))”
สมการ: \[Y = \beta_0 + \beta_1 X + \epsilon\]
แนวคิด: เปรียบเสมือนการพยายามลากเส้นตรงเส้นเดียวให้ “ใกล้ชิด” กับจุดข้อมูลทั้งหมดมากที่สุด
ตัวอย่าง: การทำนาย ยอดขาย (\(Y\)) โดยดูจาก งบโฆษณา (\(X\)) เพียงอย่างเดียว หากงบเพิ่มขึ้น ยอดขายควรเพิ่มขึ้นตามในสัดส่วนที่คงที่
11.2.2 แบบจำลอง: การถดถอยเชิงเส้นพหุคูณ(Multiple Linear Regression)
ในโลกความเป็นจริง ผลลัพธ์หนึ่งอย่างมักถูกกำหนดโดยปัจจัยหลายด้าน เราจึงต้องใช้ตัวแปรอิสระหลายตัว (\(X_1, X_2, ..., X_n\)) เข้ามาช่วยทำนายเพื่อให้แบบจำลองแม่นยำขึ้น
สมการ \[Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + ... + \beta_nX_n + \epsilon\]
แนวคิด: การหาความสัมพันธ์ที่ซับซ้อนขึ้น เช่น ราคาคอนโดไม่ได้ขึ้นอยู่กับ “พื้นที่” เท่านั้น แต่ยังขึ้นอยู่กับ “ชั้นที่อยู่”, “ระยะห่างจากรถไฟฟ้า” และ “อายุของตึก” ด้วย
จุดเด่น: ช่วยให้นักวิเคราะห์ข้อมูลเข้าใจได้ว่า ตัวแปรใดมีอิทธิพลต่อผลลัพธ์มากที่สุด (Feature Importance)
11.2.3 หลักการพยากรณ์และการวัดประสิทธิภาพ
ก่อนที่เราจะตัดสินใจเลือกแบบจำลองใดมาใช้งาน เราต้องมี “มาตรวัด” ที่บอกได้ว่าสิ่งที่เครื่องเรียนรู้นั้นมีคุณภาพเพียงใด โดยมีเครื่องมือสำคัญ 3 ตัวดังนี้
ความสัมพันธ์เชิงเส้น (Correlation: \(r\)) คือการดูว่าตัวแปร \(X\) และ \(Y\) “เดินไปด้วยกัน” หรือไม่ ก่อนที่จะเริ่มสร้างแบบจำลอง
ถ้า \(r\) เข้าใกล้ \(1\): \(X\) เพิ่ม \(Y\) เพิ่ม (ไปทางเดียวกัน)
ถ้า \(r\) เข้าใกล้ \(-1\): \(X\) เพิ่ม \(Y\) ลด (สวนทางกัน)
จุดสังเกต: หาก \(X\) และ \(Y\) ไม่มีความสัมพันธ์กันเลย (\(r \approx 0\)) การใช้ Linear Regression ก็อาจจะได้ผลลัพธ์ที่ไม่แม่นยำ
สัมประสิทธิ์การตัดสินใจ (Coefficient of Determination: \(R^2\)) คือมาตรวัดว่า **“ตัวแปร** \(X\) ที่เราเลือกมานั้น สามารถอธิบายความผันแปรของ \(Y\) ได้กี่เปอร์เซ็นต์”
\(R^2\) มีค่าตั้งแต่ \(0\) ถึง \(1\) (หรือ \(0\%\) - \(100\%\))
เช่น \(R^2 = 0.85\) หมายความว่า ปัจจัยที่เราใส่ในแบบจำลอง (เช่น งบโฆษณาและวันหยุด) สามารถอธิบายยอดขายได้ถึง \(85\%\) ส่วนอีก \(15\%\) ที่เหลือเกิดจากปัจจัยอื่นๆ ที่เราไม่ได้เก็บข้อมูลมา
ในทางปฏิบัติ: ยิ่ง \(R^2\) สูง แบบจำลองยิ่ง “ฟิต” (Fit) กับข้อมูลได้ดี
การเลือกแบบจำลอง (Model Selection) ในโลกของการเรียนรู้ของเครื่อง เรามักจะไม่ได้สร้างแค่แบบจำลองเดียว แต่เราจะสร้างหลายๆ แบบจำลองเพื่อเปรียบเทียบกัน เช่น
แบบจำลอง A: ใช้แค่
งบโฆษณา(\(R^2 = 0.60\))แบบจำลอง B: ใช้
งบโฆษณา+วันหยุด(\(R^2 = 0.82\))หลักการเลือก: เรามักจะเลือกแบบจำลองที่ให้ค่า \(R^2\) สูงกว่า แต่ต้องระวังไม่ให้แบบจำลองซับซ้อนเกินไปจนจำข้อมูลแม่นแค่ในอดีตแต่ทำนายอนาคตไม่ได้ (เรียกว่า Overfitting)
สำหรับการประเมินผลแบบจำลองการพยากรณ์นั้น นอกจาก \(R^2\) ที่บอกถึง “สัดส่วนความสามารถในการอธิบาย” แล้ว เรายังจำเป็นต้องใช้กลุ่มมาตรวัดค่าความผิดพลาด (Error Metrics) เพื่อดูว่าผลการพยากรณ์นั้น “ห่าง” จากความเป็นจริงมากแค่ไหน
- Mean Squared Error (MSE) เป็นพื้นฐานของการวัดความคลาดเคลื่อนที่เน้นบทลงโทษสำหรับข้อผิดพลาดขนาดใหญ่
- สูตรการคำนวณ:
\[MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2\]
เงื่อนไขการใช้: เหมาะสำหรับใช้ในขั้นตอนการ Training เพื่อปรับจูนแบบจำลอง เนื่องจากคุณสมบัติทางคณิตศาสตร์ที่หาอนุพันธ์ได้ง่าย
ข้อควรระวัง: หน่วยของ MSE จะเป็น “หน่วยยกกำลังสอง” ทำให้ตีความเข้ากับข้อมูลจริงได้ยาก และอ่อนไหวต่อค่าผิกปกติ (Outliers) มาก (เพราะความผิดพลาดถูกยกกำลังสอง)
- Root Mean Squared Error (RMSE) คือการถอดรากที่สองของ MSE เพื่อให้หน่วยกลับมาเป็นหน่วยเดียวกับตัวแปรตาม (\(y\))
- สูตรการคำนวณ:
\[RMSE = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2}\]
เงื่อนไขการใช้: เป็นมาตรฐานสากลที่นิยมใช้ที่สุดในงานวิจัย เพราะมีหน่วยเดียวกับข้อมูลจริง (เช่น เป็น “บาท” หรือ “คะแนน”)
ข้อดี: ยังคงให้ความสำคัญกับค่าคาดเคลื่อนขนาดใหญ่ (ถ้า RMSE สูง แสดงว่ามีบางจุดที่แบบจำลองทายผิดพลาดอย่างรุนแรง)
- Mean Absolute Error (MAE) วัดค่าเฉลี่ยของความคลาดเคลื่อนในรูปของ “ระยะห่างสัมบูรณ์”
- สูตรการคำนวณ:
\[MAE = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i|\]
เงื่อนไขการใช้: เหมาะสำหรับข้อมูลที่มีความผิดปกติปนอยู่เยอะ เพราะ MAE จะไม่ขยายขนาดความผิดพลาดด้วยการยกกำลังสอง (มีความแกร่ง (Robust) มากกว่า RMSE) [3]
การตีความ: เข้าใจง่ายที่สุด เช่น “โดยเฉลี่ยแล้วแบบจำลองพยากรณ์ผิดไป \(\pm\) 5 หน่วย”
- Mean Absolute Percentage Error (MAPE) วัดค่าความคลาดเคลื่อนออกมาในรูปของ เปอร์เซ็นต์ (%)
- สูตรการคำนวณ:
\[MAPE = \frac{100\%}{n} \sum_{i=1}^{n} \left| \frac{y_i - \hat{y}_i}{y_i} \right|\]
เงื่อนไขการใช้: เหมาะสำหรับ การนำเสนอต่อผู้บริหาร หรือคนที่ไม่ใช่นักสถิติ เพราะการบอกว่า “แบบจำลองผิดพลาด 5%” เข้าใจง่ายกว่าบอกว่า “ผิดพลาด 500 บาท”
ข้อควรระวัง: ห้ามใช้ ถ้าข้อมูลจริง (\(y_i\)) มีค่าเป็น 0 เพราะจะทำให้เกิดการหารด้วยศูนย์ และไม่เหมาะกับข้อมูลที่มีค่าเข้าใกล้ 0 มากๆ เพราะจะทำให้ค่า MAPE พุ่งสูงผิดปกติ
11.2.4 ตัวอย่าง การวิเคราะห์งบโฆษณาด้วยวิธีการเรียนรู้ของเครื่อง
ในแนวทางของการเรียนรู้ของเครื่องเราจะถามว่า “ถ้าใส่ตัวแปรนี้เข้าไปแล้ว แบบจำลองจะทายแม่นขึ้นหรือไม่?” โดยใช้ \(R^2\) และค่าความคลาดเคลื่อนเป็นตัวตัดสิน
- การเตรียมข้อมูลและสำรวจ (Data Setup)
เราจะใช้ชุดข้อมูลเดิม (TV, Radio, Newspaper) เพื่อสร้างแบบจำลองพยากรณ์ยอดขาย
นักศึกษาสามารถ download ข้อมูลจาก
ตัวอย่างชุดข้อมูล
คำนวณค่าเมทริกซ์สหสัมพันธ์ (Correlation Matrix)
| TV | Radio | Newspaper | Sales | |
|---|---|---|---|---|
| TV | 1.000 | -0.053 | -0.069 | 0.740 |
| Radio | -0.053 | 1.000 | -0.074 | 0.543 |
| Newspaper | -0.069 | -0.074 | 1.000 | -0.097 |
| Sales | 0.740 | 0.543 | -0.097 | 1.000 |
จากตารางเมทริกซ์สหสัมพันธ์ ซึ่งเป็นการวัดระดับความสัมพันธ์เบื้องต้นระหว่างตัวแปร สามารถอธิบายได้ดังนี้
ตัวแปรที่มีผลต่อยอดขายมากที่สุด
TV (0.740): มีความสัมพันธ์เชิงบวกสูงที่สุดกับยอดขาย แสดงว่าเป็นพยานหลักฐานชิ้นสำคัญในการพยากรณ์
Radio (0.543): มีความสัมพันธ์เชิงบวกปานกลาง มีผลต่อยอดขายรองลงมา
ตัวแปรที่แทบไม่มีผล
- Newspaper (-0.097): มีค่าเข้าใกล้ 0 และติดลบน้อยมาก แสดงว่าการขึ้นหรือลงของงบโฆษณาหนังสือพิมพ์ แทบไม่มีผล หรือไม่มีความสัมพันธ์เชิงเส้นกับยอดขายในชุดข้อมูลนี้เลย
ความอิสระของตัวแปรต้น
- งบโฆษณาทั้ง 3 ช่องทาง (TV, Radio, Newspaper) มีค่า Correlation ระหว่างกันเองต่ำมาก (ใกล้ 0) หมายความว่าแต่ละตัวแปรเป็นอิสระต่อกัน ไม่ซ้ำซ้อนกันเอง
การสร้างและเปรียบเทียบแบบจำลอง (Model Selection by \(R^2\))
ในการวิเคราะห์หาตัวแบบที่ดีที่สุด เราจะทดลองสร้างแบบจำลองที่มีความซับซ้อนต่างกัน 3 ระดับ เพื่อพิสูจน์ว่าพยานหลักฐานชุดใด (Features) ที่ส่งผลต่อความแม่นยำในการพยากรณ์ยอดขายมากที่สุด ดังนี้
แบบจำลอง 1 (Simple): พยากรณ์จากงบ TV เพียงอย่างเดียว \[Sales = \beta_0 + \beta_1(TV) + \epsilon\]
แบบจำลอง 2 (Multiple): พยากรณ์จากงบ TV ร่วมกับ Radio \[Sales = \beta_0 + \beta_1(TV) + \beta_2(Radio) + \epsilon\]
แบบจำลอง 3 (Full): พยากรณ์จากงบโฆษณาทุกช่องทาง \[Sales = \beta_0 + \beta_1(TV) + \beta_2(Radio) + \beta_3(Newspaper) + \epsilon\]
ผลการเปรียบเทียบประสิทธิภาพ (R-Squared Comparison):
| แบบจำลองพยากรณ์ | ค่า R-Squared (ความแม่นยำ) |
|---|---|
| Model 1: TV Only | 0.5477 |
| Model 2: TV + Radio | 0.8872 |
| Model 3: All Channels | 0.8872 |
เมื่อเราเพิ่ม Radio เข้าไปในแบบจำลอง2 ค่า \(R^2\) เพิ่มขึ้นอย่างมีนัยสำคัญจากตัวแบบแรก แสดงว่า Radio เป็นพยานชิ้นสำคัญที่มีพลังในการพยากรณ์สูง
พยานส่วนเกิน: ในแบบจำลอง3 เมื่อเราใส่
Newspaperเพิ่มเข้าไป ค่า \(R^2\) แทบไม่มีการเปลี่ยนแปลง (หรือเพิ่มขึ้นน้อยมากในทศนิยมตำแหน่งท้ายๆ) สิ่งนี้พิสูจน์ให้เห็นว่า Newspaper ไม่มีพลังในการช่วยทำนายยอดขาย ในชุดข้อมูลนี้การเลือกใช้งาน: เราควรเลือกแบบจำลอง2 เนื่องจากมีความแม่นยำสูงและมีความซับซ้อนที่เหมาะสม (Parsimony) ตามหลักการเลือกแบบจำลองในด้วยวิทยาการข้อมูล
- การวิเคราะห์อิทธิพลของตัวแปร (Feature Importance)
แทนที่จะดู \(p\text{-value}\) เราจะดูที่ค่า Coefficient (\(\beta\)) เพื่อเปรียบเทียบน้ำหนักว่าช่องทางไหน สามารถเพิ่มยอดขายได้มากกว่ากัน
| Variable | Impact_Weight |
|---|---|
| (Intercept) | 7.3079789 |
| TV | 0.0450490 |
| Radio | 0.1911382 |
| Newspaper | -0.0000525 |
- การตีความหมายของน้ำหนัก (Impact Weight)
ค่าสัมประสิทธิ์เหล่านี้บอกเราว่า “หากเราเพิ่มงบโฆษณา 1 หน่วย (บาท/เหรียญ) ยอดขายจะเปลี่ยนแปลงไปอย่างไร” โดยสมมติให้ตัวแปรอื่นคงที่:
Radio (0.191): ส่งผลต่อยอดขายที่สุด ในเชิงการเรียนรู้ของเครื่องนี่คือตัวแปรที่มีน้ำหนักมากที่สุด การลงทุนในวิทยุเพียง 1 หน่วย สามารถกระตุ้นยอดขายได้สูงถึง 0.191 หน่วย ซึ่งถือเป็น “ช่องทางที่คุ้มค่าที่สุด” ในแง่สัดส่วนการลงทุน
TV (0.045): ส่งผลบวกแต่มีน้ำหนักน้อยกว่า งบ TV ยังคงมีผลในทางบวกต่อยอดขาย แต่ส่งผลน้อยกว่าวิทยุประมาณ 4 เท่า (0.045 เทียบกับ 0.191) แสดงว่าหากมีงบประมาณจำกัด การเพิ่มงบใน Radio อาจให้ผลลัพธ์ที่รวดเร็วกว่า
Newspaper (-0.00005): ไม่มีอิทธิพล น้ำหนักของหนังสือพิมพ์มีค่า เกือบเป็นศูนย์ และติดลบเล็กน้อย ซึ่งในทางปฏิบัติหมายความว่า “งบหนังสือพิมพ์ไม่มีผลต่อยอดขายเลย” ไม่ว่าเราจะทุ่มงบเพิ่มหรือลดงบส่วนนี้ ยอดขายก็แทบจะไม่ขยับ
(Intercept) (7.307): ยอดขายพื้นฐาน ค่า 7.307 คือ “ยอดขายที่เกิดขึ้นแน่ๆ” แม้ว่าเราจะไม่ได้ลงโฆษณาในช่องทางใดเลย (Base Sales)
กลยุทธ์เชิงรุก (Focus): ควรจัดลำดับความสำคัญของงบประมาณไปที่ Radio และ TV ตามลำดับ กลยุทธ์ลดต้นทุน (Optimize): เราสามารถ “ตัดงบโฆษณา Newspaper ออกได้ทั้งหมด” โดยไม่ส่งผลกระทบต่อยอดขาย เพื่อนำเงินส่วนนั้นไปลงในช่องทางที่ให้ Impact สูงกว่า
คำถาม ถ้าพรุ่งนี้เรามีงบ TV 100 และ Radio 50 ยอดขายจะเป็นเท่าไหร่?
11.3 การจำแนกประเภท (Classification)
คือการใช้การเรียนรู้ของเครื่อง เพื่อทำนายผลลัพธ์ที่เป็น “กลุ่ม” (Categories) หรือ “สถานะ” (States) ของพยานหลักฐานที่เราสนใจ โดยคำตอบจะเป็นค่าที่แบ่งแยกออกจากกันอย่างชัดเจน
11.3.1 แบบจำลอง: การถดถอยแบบโลจิสติก (Logistic Regression)
แม้ชื่อจะดูเหมือนสมการถดถอยแต่ในทางการเรียนรู้ของเครื่อง เราใช้ตัวแบบนี้สำหรับการจำแนกประเภท (Classification) โดยแทนที่จะทำนายค่าตัวเลขโดยตรง แบบจำลองนี้จะทำนาย “ความน่าจะเป็น” (Probability) ว่าข้อมูลนั้นจะตกอยู่ในกลุ่มใดกลุ่มหนึ่ง
แนวคิด: เครื่องจะคำนวณความน่าจะเป็นระหว่าง \(0\) ถึง \(1\) หากค่าสูงกว่า \(0.5\) จะถูกจัดว่าเป็นกลุ่มที่สนใจ (เช่น Churn)
ตัวอย่าง: การทำนายว่า อีเมลเป็น Spam หรือไม่? โดยดูจาก “จำนวนคำโฆษณา” ในเนื้อหาอีเมล หากความน่าจะเป็นของ Spam สูงกว่าเกณฑ์ที่ตั้งไว้ ระบบจะย้ายอีเมลนั้นเข้าโฟลเดอร์ขยะทันที [4]
11.3.2 การแสดงผลทางภาพของการถดถอย (The Sigmoid Curve)
ในงานการจำแนกประเภทแบบการถดถอยเราไม่ได้ทำนายค่าเป็นเส้นตรงเหมือนแบบจำลองการถดถอยทั่วไป แต่เราทำนาย “โอกาสที่จะเกิดขึ้น” (\(P\)) ซึ่งมีค่าระหว่าง \(0\) ถึง \(1\) โดยใช้ฟังก์ชันทางคณิตศาสตร์ที่เรียกว่า Logit Function
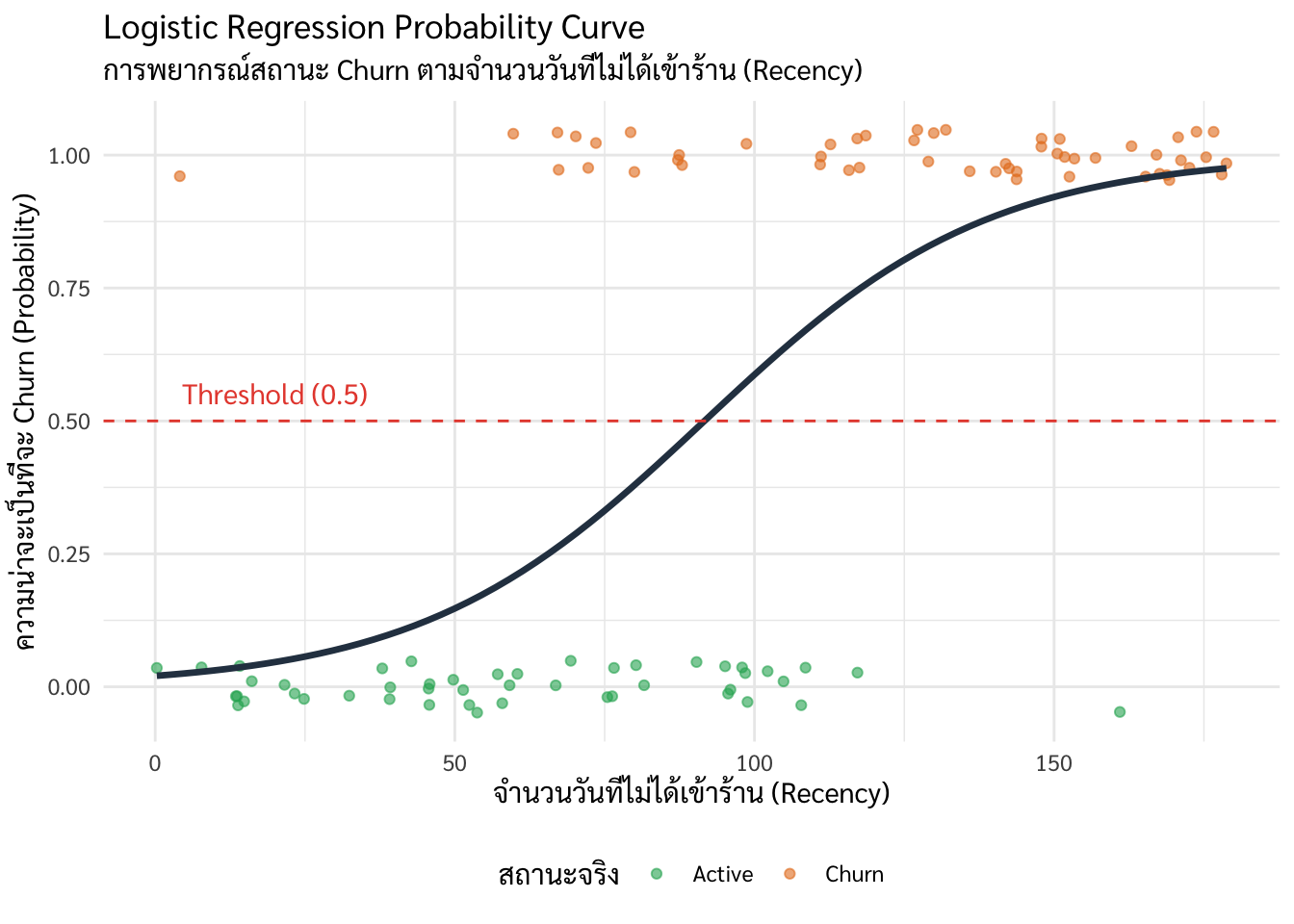
จาก Figure 11.1
จุดข้อมูล (Data Points): จุดสีเขียวด้านล่างคือลูกค้าที่ยังอยู่ (Active) และจุดสีส้มด้านบนคือลูกค้าที่เลิกไปแล้ว (Churn)
เส้นโค้งรูปตัว S (Sigmoid Curve): นี่คือหัวใจของ Logistic Regression เส้นนี้บอกความน่าจะเป็น (0 ถึง 1) ยิ่งกราฟขยับไปทางขวา (Recency มากขึ้น) เส้นสีดำจะค่อยๆ สูงขึ้น แสดงว่าโอกาสที่ลูกค้าจะ Churn นั้นเพิ่มขึ้นตามไปด้วย
Decision Threshold (0.5): ในทาง ML เรามักใช้จุดตัดที่ \(0.5\) เป็นเกณฑ์ตัดสินใจ หากจุดใดมีค่าบนเส้นโค้งเกิน \(0.5\) แบบจำลองจะทายว่าคนนั้นคือ “Churn” ทันที
11.3.3 แบบจำลอง: ต้นไม้ตัดสินใจ (Decision Tree)
เป็นแบบจำลองที่เข้าใจง่ายที่สุดและได้รับความนิยมสูงมาก เพราะเลียนแบบกระบวนการตัดสินใจของมนุษย์ผ่านการสร้าง “แผนผังต้นไม้”
แนวคิด: เครื่องจะทำการแยกข้อมูล (Split) ตามเงื่อนไขของตัวแปร \(X\) ที่สำคัญที่สุดไปเรื่อยๆ จนถึงปลายกิ่งที่เป็นคำตอบ \(Y\)
ตัวอย่าง: การทำนายว่า ลูกค้าจะ Churn หรือไม่
เงื่อนไขที่ 1: ลูกค้ามาใช้บริการครั้งล่าสุดเกิน 90 วันหรือไม่? (ถ้าใช่ ไปกิ่งขวา)
เงื่อนไขที่ 2: ลูกค้ามียอดใช้จ่ายรวมต่ำกว่า 500 บาทหรือไม่? (ถ้าใช่ สรุปว่า Churn)
จุดเด่น: สามารถอธิบายผลลัพธ์ให้เจ้าของธุรกิจเข้าใจได้ง่ายมาก (High Interpretability)
11.3.4 การแสดงผลทางภาพของต้นไม้การตัดสินใจ (Visualization)
เมื่อเครื่องทำการเรียนรู้แบบต้นไม้การตัดสินใจ ผลลัพธ์ที่ได้จะไม่ใช่สมการคณิตศาสตร์ที่ซับซ้อน แต่เป็น “ชุดเงื่อนไข” ที่มนุษย์สามารถอ่านและทำความเข้าใจตามได้ทันที ดังแสดงในภาพด้านล่างนี้
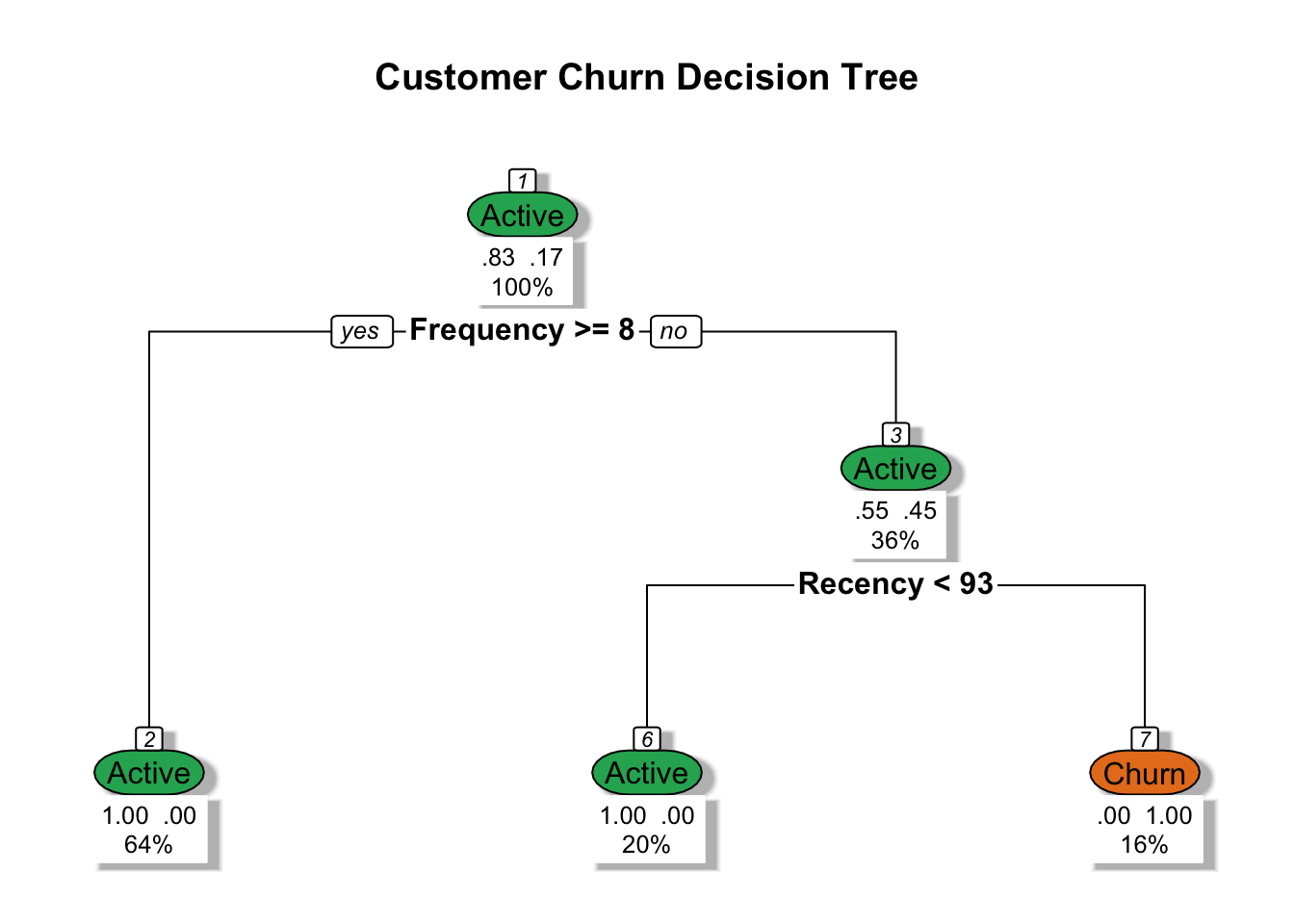
โหนดบนสุด (Root Node): คือตัวแปรที่ “สำคัญที่สุด” ในการแยกกลุ่มข้อมูล ในที่นี้คือ
Recency(จำนวนวันที่หายไป)กิ่งก้าน (Edges): คือเกณฑ์การตัดสินใจ (Threshold) เช่น หาก
Recency <= 0วัน เครื่องจะส่งข้อมูลไปพิจารณาต่อทางซ้ายโหนดปลายทาง (Leaf Nodes): คือข้อสรุปสุดท้ายของกลุ่มนั้นๆ เช่น หากผ่านเงื่อนไขมาถึงกล่องสีส้ม แบบจำลองจะพยากรณ์ว่าลูกค้าคนนี้คือกลุ่ม “Churn”
11.4 การวัดประสิทธิภาพของการจำแนกประเภท (The Metrics)
ในทางการเรียนรู้ของเครื่อง เราจะไม่ใช้ \(R^2\) กับงานการจำแนกประเภท แต่เราจะมองไปที่
ความแม่น (Accuracy): ทายถูกกี่เปอร์เซ็นต์จากทั้งหมด
เมตริกซ์ความสับสน (Confusion Matrix): ตารางพิสูจน์ความผิดพลาด (ทายว่า Churn แต่จริงๆ ไม่ Churn เท่าไหร่ / ทายว่า Active แต่จริงๆ Churn เท่าไหร่)
11.4.1 การประเมินผลด้วยเมตริกซ์ความสับสน (Confusion Matrix)
เมตริกซ์ความสับสน คือตารางสรุปประสิทธิภาพของแบบจำลอง โดยการเปรียบเทียบระหว่าง “คำตอบที่แบบจำลองทาย (Predicted)” กับ “ความจริงที่เป็นอยู่ (Actual)” ซึ่งจะช่วยให้เราเห็นว่าแบบจำลองมีความสับสนในจุดใด
| ความจริง: Positive (1) | ความจริง: Negative (0) | |
|---|---|---|
| แบบจำลองทาย: Positive (1) | TP (True Positive) | FP (False Positive) |
| แบบจำลองทาย: Negative (0) | FN (False Negative) | TN (True Negative) |
TP (ทายถูก): ของจริงเป็น Churn แบบจำลองก็ทายว่า Churn
TN (ทายถูก): ของจริงไม่ Churn แบบจำลองก็ทายว่าไม่ Churn
FP (ทายผิด): ของจริงไม่ Churn แต่แบบจำลองทายว่า Churn (เรียกว่า Type I Error หรือ “ตื่นตูม”)
FN (ทายผิด): ของจริงเป็น Churn แต่แบบจำลองทายว่าไม่ Churn (เรียกว่า Type II Error หรือ “นิ่งนอนใจ”)
จาก Table 11.2 ด้านบน เราสามารถคำนวณค่าเพื่อประเมินแบบจำลองได้ดังนี้
ความแม่นยำ (Accuracy): ภาพรวมว่าแบบจำลองทายถูกมากน้อยแค่ไหน \[Accuracy = \frac{TP + TN}{TP + TN + FP + FN}\]
ความเที่ยง (Precision): เมื่อแบบจำลองทายว่า “จะ Churn” มันแม่นยำแค่ไหน \[Precision = \frac{TP}{TP + FP}\]
การเรียกคืน (Recall): ในบรรดาคนที่ “Churn จริงๆ” แบบจำลองเก็บกวาดมาได้ครบไหม \[Recall = \frac{TP}{TP + FN}\]
F1-Score: ค่าเฉลี่ยแบบฮามอนิก (Harmonic) ระหว่าง ึวามเที่ยง (Precision) และการเรียกคืน (Recall ) (ใช้เมื่อกลุ่มข้อมูลมีสัดส่วนไม่สมดุลกัน) \[F1 = 2 \times \frac{Precision \times Recall}{Precision + Recall}\]
ในฐานะนักวิเคราะห์ข้อมูลงานของคุณไม่ใช่แค่การสร้างแบบจำลองที่ตัวเลขสวยที่สุด แต่คือการตอบคำถามให้ได้ว่า ‘ความผิดพลาดแบบไหนที่ธุรกิจของคุณรับไม่ได้?’ แล้วจงเลือกใช้ตัววัดนั้นเป็นเข็มทิศในการปรับจูนแบบจำลอง
หลังจากที่เราได้เรียนรู้วิธีการสร้างแบบจำลองและมาตรวัดต่าง ๆ ไปแล้ว คำถามสำคัญที่ตามมาคือ “แบบจำลองที่ทายแม่นที่สุด คือแบบจำลองที่ดีที่สุดจริงหรือ?” ในโลกของวิทยาการข้อมูลเราไม่ได้สร้างแบบจำลองเพื่อไปทายข้อมูลที่เรา “รู้คำตอบอยู่แล้ว” (Training Data) แต่เป้าหมายที่แท้จริงคือการสร้างแบบจำลองที่สามารถนำไปทำนาย “ข้อมูลในอนาคต” ที่เครื่องไม่เคยเห็นมาก่อนได้อย่างถูกต้องแม่นยำ
ความท้าทายที่ยิ่งใหญ่ที่สุดของนักวิเคราะห์ข้อมูลคือการหา “จุดสมดุล” ระหว่างการเรียนรู้รูปแบบ (Learning Pattern) และการท่องจำข้อมูล (Memorizing Data) ซึ่งหากเราทำแบบจำลองให้ซับซ้อนเกินไปหรือเรียบง่ายเกินไป จะนำไปสู่ปัญหาที่เรียกว่า Underfitting และ Overfitting ดังนี้
11.5 Overfitting และ Underfitting (ปัญหาความพอดีของแบบจำลอง)
เป้าหมายของการเรียนรู้ของเครื่อง คือการสร้างแบบจำลองที่มีความทั่วไป (Generalization) หรือความสามารถในการนำไปใช้ทำนายข้อมูลใหม่ๆ ได้อย่างแม่นยำ แต่ในระหว่างการฝึกสอน (Training) มักจะเกิดปัญหาความไม่สมดุล 2 ลักษณะ
เพื่อป้องกันปัญหา Overfitting และ Underfitting เราจึงต้องมี “ระเบียบวิธี” ในการตรวจสอบพยานหลักฐานอย่างเป็นระบบ โดยมี 2 วิธีมาตรฐานที่นิยมใช้กันมากที่สุดในทางปฏิบัติ
11.5.1 Train and Test Split (การแบ่งข้อมูล)
เป็นวิธีที่ง่ายและตรงไปตรงมาที่สุด โดยเราจะแบ่งข้อมูลที่มีอยู่ทั้งหมดออกเป็น 2 ส่วน:
Training Set (80%): เปรียบเสมือน “หนังสือเรียน” ที่เราให้แบบจำลองใช้ศึกษาหา Pattern และจำลองกฎเกณฑ์ต่าง ๆ ขึ้นมา
Test Set (20%): เปรียบเสมือน “ข้อสอบไล่” ที่เราเก็บซ่อนไว้ ไม่ให้แบบจำลองเห็นในขณะฝึกสอน เพื่อใช้ทดสอบความแม่นยำกับข้อมูลใหม่จริง ๆ
จุดเด่น: รวดเร็ว เหมาะกับชุดข้อมูลที่มีปริมาณมากพอ
11.5.2 การทดสอบแบบหมุนเวียน (K-Fold Cross Validation)
ในกรณีที่ข้อมูลมีจำกัด การแบ่งแค่ครั้งเดียวอาจทำให้เกิดความลำเอียง (Bias) ได้ เช่น ส่วนที่แบ่งไปเป็นข้อสอบดันเป็นส่วนที่ง่ายเกินไป เราจึงใช้วิธี K-Fold มาแก้ปัญหา:
หลักการ: แบ่งข้อมูลออกเป็น \(K\) ส่วนเท่า ๆ กัน (ปกติมักใช้ \(K = 5\) หรือ \(10\))
กระบวนการ: ในการทดสอบแต่ละรอบ เราจะเลือก 1 ส่วนมาเป็น Test Set และที่เหลือเป็น Training Set สลับกันไปเรื่อย ๆ จนครบทุกส่วน
ผลลัพธ์: เราจะได้ค่าความแม่นยำเฉลี่ยจากการทดสอบทั้ง \(K\) ครั้ง ซึ่งจะสะท้อนความเก่งที่แท้จริงของแบบจำลองได้ดีกว่าการวัดผลเพียงครั้งเดียว
จุดเด่น: มีความเสถียรสูงมาก ช่วยลดความเสี่ยงจากการที่ข้อมูลบางส่วนมีค่าผิดปกติ (Outliers)
11.6 กรณีศึกษา: รู้จักกับ Student Performance Dataset
Student Performance Dataset เป็นชุดข้อมูลมาตรฐาน (Benchmark Dataset) จาก UCI Machine Learning Repository ที่รวบรวมโดย Paulo Cortez และคณะ ข้อมูลชุดนี้ได้มาจากแบบสอบถามและผลการเรียนของนักศึกษาระดับมัธยมปลายในโปรตุเกส 2 แห่ง โดยแบ่งเป็นวิชาคณิตศาสตร์ (Math) และวิชาภาษาโปรตุเกส (Portuguese)
สิ่งที่ทำให้ชุดข้อมูลนี้โดดเด่นคือ ไม่ได้มีแค่ “คะแนนสอบ” เท่านั้น แต่ยังมี “ข้อมูลเชิงพฤติกรรมและสังคม” (Social & Behavioral Features) [8] กว่า 30 ตัวแปร เช่น
พฤติกรรมส่วนตัว: การดื่มแอลกอฮอล์ในวันธรรมดาและวันหยุด (
Dalc,Walc), เวลาในการเรียน (studytime), ความถี่ในการออกไปเที่ยวกับเพื่อน (goout)พื้นฐานครอบครัว: ระดับการศึกษาของพ่อแม่ (
Medu,Fedu), สถานะความสัมพันธ์ในครอบครัว (famrel)ปัจจัยสนับสนุน: การใช้อินเทอร์เน็ตที่บ้าน (
internet), การเรียนพิเศษนอกเวลา (paid)
11.6.1 การเตรียมข้อมูล (UCI Student Performance)
เราจะดึงข้อมูลมาทำความสะอาดและเปลี่ยนเป้าหมายให้เป็นการจำแนกประเภท 2 ทาง (สอบผ่าน/สอบตก) โดยใช้เกณฑ์คะแนน 10 จาก 20
ตัวอย่างข้อมูลสำหรับการเรียนรู้
| Status | studytime | failures | absences | schoolsup | goout | Medu | |
|---|---|---|---|---|---|---|---|
| 3 | Pass | 2 | 3 | 10 | yes | 2 | 1 |
| 4 | Pass | 3 | 0 | 2 | no | 2 | 4 |
| 5 | Pass | 2 | 0 | 4 | no | 2 | 3 |
| 6 | Pass | 2 | 0 | 10 | no | 2 | 4 |
| 7 | Pass | 2 | 0 | 0 | no | 4 | 2 |
| 8 | Fail | 2 | 0 | 6 | yes | 4 | 4 |
ตัวอย่างข้อมูลสำหรับการทดสอบ
| Status | studytime | failures | absences | schoolsup | goout | Medu | |
|---|---|---|---|---|---|---|---|
| 1 | Fail | 2 | 0 | 6 | yes | 4 | 4 |
| 2 | Fail | 2 | 0 | 4 | no | 3 | 1 |
| 9 | Pass | 2 | 0 | 0 | no | 2 | 3 |
| 12 | Pass | 3 | 0 | 4 | no | 2 | 2 |
| 19 | Fail | 1 | 3 | 16 | no | 5 | 3 |
| 20 | Pass | 1 | 0 | 4 | no | 3 | 4 |
11.6.2 แบบจำลองทางคณิตศาสตร์ของการถดถอยแบบโลจิสติก
ในโจทย์การพยากรณ์ผลการเรียนนี้ เราต้องการหาความน่าจะเป็นที่นักศึกษาจะ สอบผ่าน (Status = Pass) โดยใช้ปัจจัยพฤติกรรม 6 ตัวแปร
- ส่วนสะสมอิทธิพล (Logit Score: \(z\)) เราจะนำพยานหลักฐาน (Features) แต่ละตัวมาคูณกับ “น้ำหนัก” (Estimate/Coefficient) ของมัน แล้วรวมเข้ากับค่าคงที่พื้นฐาน (Intercept):
\[\begin{aligned*}z =& \beta_0 + \beta_1(studytime) \\\nonumber &+ \beta_2(failures) + \beta_3(absences) \\\nonumber &+ \beta_4(schoolsup) + \beta_5(goout) + \beta_6(Medu) \nonumber\end{aligned*}\]
โดยที่ \(\beta_n\) คือค่าน้ำหนักที่เครื่องจะทำการ “เรียนรู้” (Learn) จากข้อมูล
- ส่วนการแปลงเป็นความน่าจะเป็น (The Logistic Function) เนื่องจากค่า \(z\) ที่ได้อาจเป็นเลขติดลบหรือเลขบวกจำนวนมาก แต่โอกาสสอบผ่านต้องอยู่ระหว่าง 0 ถึง 1 (0% - 100%) เท่านั้น เราจึงต้องส่ง \(z\) เข้าไปในฟังก์ชันพยากรณ์:
\[P(Pass) = \frac{1}{1 + e^{-z}}\]
Direction (เครื่องหมาย):
- ตัวแปรไหนที่มีเครื่องหมายเป็น บวก (+) เช่น
studytimeยิ่งมาก จะยิ่งดึงกราฟขึ้นไปหา 1 (Pass) - ตัวแปรไหนที่มีเครื่องหมายเป็น ลบ (-) เช่น
failuresหรือabsencesยิ่งมาก จะยิ่งดึงกราฟลงไปหา 0 (Fail)
- ตัวแปรไหนที่มีเครื่องหมายเป็น บวก (+) เช่น
Magnitude (ขนาดของเลข): ตัวแปรที่มีค่าสัมประสิทธิ์สูงที่สุด (เช่น
failures) คือ “พยานคนสำคัญ” ที่มีผลต่อคำตอบมากที่สุดThe Threshold: สุดท้ายเราจะใช้จุดตัดที่ 0.5
- ถ้า \(P(Pass) \geq 0.5 \rightarrow\) พยากรณ์ว่า สอบผ่าน (Pass)
- ถ้า \(P(Pass) < 0.5 \rightarrow\) พยากรณ์ว่า สอบตก (Fail)
นำผลที่ได้จากไปทำการทดสอบ โดยใช้เมตริกซ์ความสับสน
| Fail | Pass | |
|---|---|---|
| Fail | 7 | 6 |
| Pass | 19 | 47 |
ต่อไปนี้ พิจารณาอีกแบบจำลองคือ
11.6.3 ตัวไม้ตัดสินใจ
เราจะดู “กฎการตัดสินใจ” ว่าปัจจัยใดคือน้ำหนักที่แท้จริงที่ทำให้เด็กสอบตก โดยหลังจากทำการเรียนรู้จากข้อมูลมูลและ จึงนำไปทดสอบกับข้อมูลที่เตรียมไว้
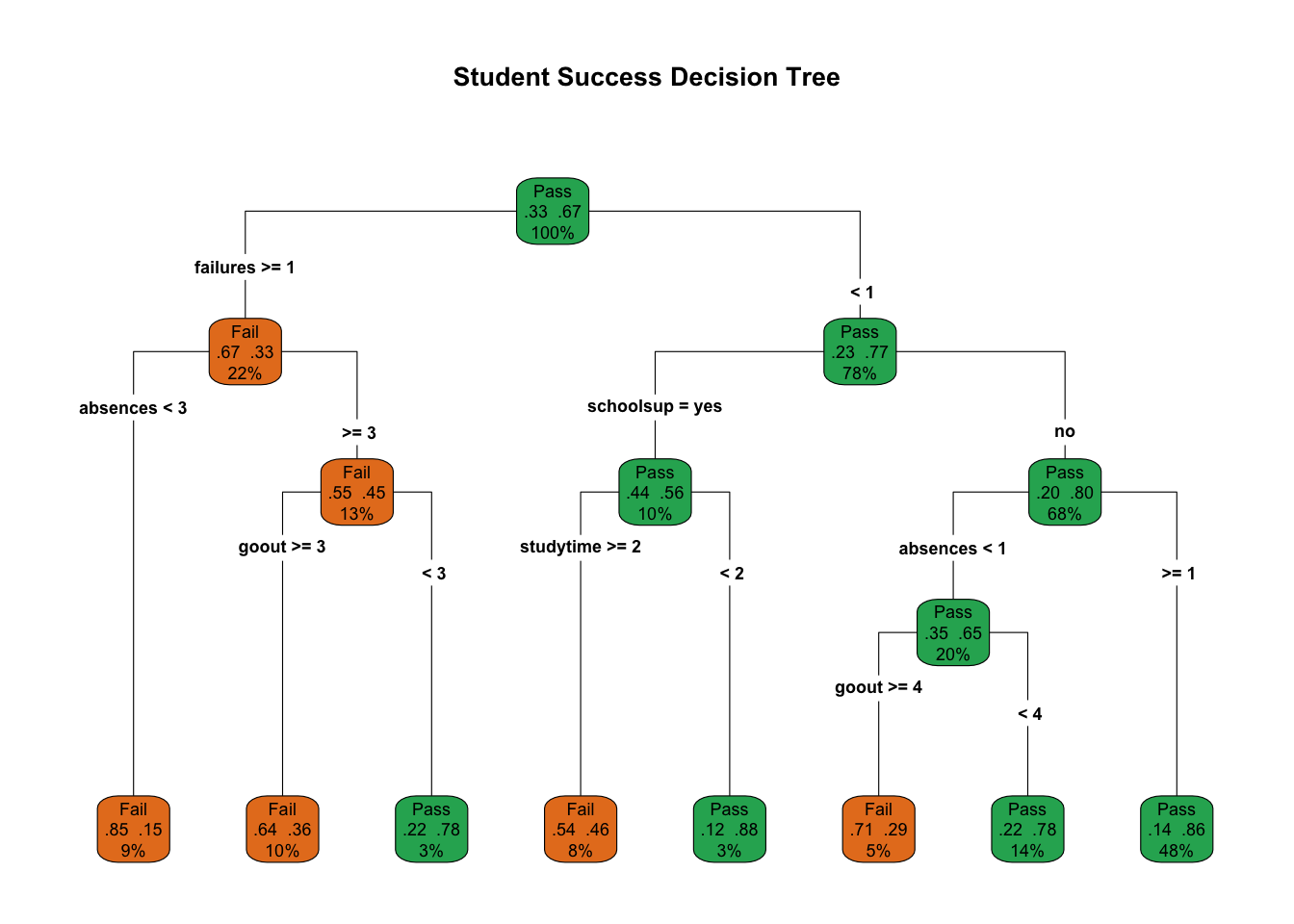
Confusion Matrix and Statistics
Reference
Prediction Fail Pass
Fail 10 12
Pass 16 41
Accuracy : 0.6456
95% CI : (0.5299, 0.75)
No Information Rate : 0.6709
P-Value [Acc > NIR] : 0.7281
Kappa : 0.1647
Mcnemar's Test P-Value : 0.5708
Sensitivity : 0.3846
Specificity : 0.7736
Pos Pred Value : 0.4545
Neg Pred Value : 0.7193
Prevalence : 0.3291
Detection Rate : 0.1266
Detection Prevalence : 0.2785
Balanced Accuracy : 0.5791
'Positive' Class : Fail
จากการทดสอบแบบจำลองทั้งสองแบบเพื่อพยากรณ์สถานะ Fail (สอบตก) ซึ่งเป็นคลาสที่เราให้ความสำคัญ (Positive Class) สามารถสรุปและเปรียบเทียบประสิทธิภาพได้ดังนี้
| Metric | Logistic Regression | Decision Tree |
|---|---|---|
| Accuracy (ความแม่นยำรวม) | 68.35% | 64.56% |
| Sensitivity / Recall (จับเด็กกลุ่มเสี่ยงได้) | 26.92% | 38.46% |
| Specificity (ทายเด็กกลุ่มผ่านถูกต้อง) | 88.68% | 77.36% |
| Balanced Accuracy (ค่าเฉลี่ยความสมดุล) | 57.80% | 57.91% |
จาก Table 11.4 พบว่า
ความแม่นยำภาพรวม (Accuracy) แบบจำลองการถดถอยแบบโลจิสติกทำคะแนนรวมได้สูงกว่าเล็กน้อย (68.35%) แต่เมื่อดูค่า No Information Rate (67.09%) จะพบว่าแบบจำลองทั้งคู่เก่งกว่าการ “เดาสุ่มว่าทุกคนจะสอบผ่าน” เพียงเล็กน้อยเท่านั้น
การตรวจจับกลุ่มเสี่ยง (Sensitivity/Recall) นี่คือจุดที่น่าสนใจ ต้นไม้ตัดสินใจมีค่า Sensitivity สูงกว่าอย่างชัดเจน (38.46% vs 26.92%)
- หมายความว่า: หากเป้าหมายของอาจารย์คือการ “ตามหาตัวเด็กที่กำลังจะสอบตกให้เจอมากที่สุด” ต้นไม้ตัดสินใจทำหน้าที่นี้ได้ดีกว่า แม้ความแม่นยำรวมจะต่ำกว่าก็ตาม
ปัญหาของพยานหลักฐาน (The Challenge)
- ค่า Kappa ของทั้งคู่ค่อนข้างต่ำ (0.17 - 0.16) สะท้อนว่าข้อมูลพฤติกรรมที่เรามี (เช่น เวลาเรียน การเที่ยว) ยังมีความซับซ้อนสูงและอาจมีตัวแปรอื่นที่ส่งผลต่อการสอบผ่าน/ตกที่เรายังไม่ได้นำมาคำนวณ
11.7 ชวนคิด
จากการประเมินพยานหลักฐานด้วยแบบจำลองทั้งสองตัว เราจะพบความจริงที่น่าสนใจว่าแบบจำลองการถดถอยแบบโลจิสติกนั้นดูเหมือนจะ ‘แม่นยำกว่า’ ในภาพรวม แต่มันกลับ ‘ตาบอด’ ต่อกลุ่มเด็กที่เสี่ยงจะสอบตก (ทายเจอแค่ 26%)
ในขณะที่แบบจำลองต้นไม้ตัดสินใจแม้จะดูซื่อๆ และมีความแม่นยำรวมต่ำกว่า แต่มันกลับ ‘หูไวตาไว’ กว่าในการจับกลุ่มเด็กที่กำลังจะลำบาก (ทายเจอ 38%)
ในทางธุรกิจศึกษา ถ้าเราต้องเลือกระบบเตือนภัยล่วงหน้า (Early Warning) บางครั้งเราอาจจะยอมเลือกแบบจำลองที่ Accuracy น้อยกว่า แต่จับกลุ่มเสี่ยงได้ครอบคลุมกว่า เพื่อที่เราจะได้ช่วยเหลือนักศึกษาได้ทันท่วงทีนั่นเอง
11.8 แบบฝึกหัดท้ายบท
จงอธิบายความแตกต่างระหว่าง ตัวแปรอิสระ (Independent Variable) และ ตัวแปรตาม (Dependent Variable) พร้อมยกตัวอย่างประกอบในเชิงธุรกิจมา 1 ตัวอย่าง
ในการวัดประสิทธิภาพของสมการถดถอยเชิงเส้น หากนักศึกษาพบว่าค่า \(R^2\) มีค่าเท่ากับ 0.85 ข้อมูลนี้บอกอะไรเราเกี่ยวกับความสัมพันธ์ระหว่างตัวแปร \(X\) และ \(Y\)?
หากค่า MSE (Mean Squared Error) ของแบบจำลอง A เท่ากับ 15.5 และแบบจำลอง B เท่ากับ 25.0 นักศึกษาควรเลือกแบบจำลองใดในการนำไปใช้งาน เพราะเหตุใด?
เพราะเหตุใดเราจึงต้องใช้ Sigmoid Function ในแบบจำลอง Logistic Regression? (คำใบ้: พิจารณาช่วงของค่าความน่าจะเป็น)
จากค่าของตารางเมตริกซ์ความสับสนไปนี้
ทายว่าสอบผ่าน และสอบผ่านจริง (TP) = 40
ทายว่าสอบตก และสอบตกจริง (TN) = 30
ทายว่าสอบผ่าน แต่ความจริงสอบตก (FP) = 10
ทายว่าสอบตก แต่ความจริงสอบผ่าน (FN) = 20
จงคำนวณหาค่า Accuracy และค่า Recall ของแบบจำลองนี้
หากนักศึกษาต้องการสร้างระบบ “ตรวจจับบัตรเครดิตที่ถูกขโมย” ซึ่งเรายอมไม่ได้เลยที่จะปล่อยให้โจรหลุดรอดไปได้ นักศึกษาควรให้ความสำคัญกับค่า Sensitivity (Recall) หรือ Precision มากกว่ากัน?
จงบอกข้อดี 1 ประการของต้นไม้ตัดสินใจที่ทำให้แบบจำลองนี้ได้รับความนิยมมากกว่าสมการถดถอยแบบโลจิสติก ในแง่ของการนำเสนอข้อมูลแก่ผู้บริหารที่ไม่เชี่ยวชาญด้านสถิติ
Overfitting คืออะไร? และนักศึกษาจะสังเกตเห็นอาการนี้ได้อย่างไรเมื่อพิจารณาผลลัพธ์จากชุดข้อมูล Training Set เทียบกับ Test Set?
การทำ 10-Fold Cross Validation ช่วยให้การประเมินผลแบบจำลองมีความน่าเชื่อถือมากกว่าการแบ่งข้อมูลแบบ Train/Test Split (80/20) เพียงครั้งเดียวอย่างไร?
ให้นักศึกษาวาดลำดับการต่อ Widget ใน Orange (Workflow) เพื่อทำการเปรียบเทียบประสิทธิภาพระหว่างแบบจำลองการถดถอยแบบโลจิสติกและต้นไม้ตัดสินใจ โดยใช้ข้อมูลจากไฟล์
student_performance.csv(ระบุชื่อ Widget ที่ใช้ทั้งหมดตามลำดับ) [9]