| Transaction_ID | Customer_Type | Menu | Price | In_Stock |
|---|---|---|---|---|
| 101 | Student | Latte | 65 | TRUE |
| 102 | Staff | Espresso | 55 | TRUE |
| 103 | Student | Cappuccino | 60 | FALSE |
| 104 | Visitor | Latte | 65 | TRUE |
2 ข้อมูลและการจัดการข้อมูล
2.1 การเปลี่ยนผ่านจากข้อมูลสู่การตัดสินใจ
กระบวนการเปลี่ยนข้อมูลดิบให้กลายเป็นสารสนเทศที่มีคุณค่า ไม่ใช่เพียงการจัดเก็บ แต่คือการสร้าง “ความหมาย” ผ่านบริบททางธุรกิจ โดยสามารถอธิบายรายละเอียดของลำดับขั้นได้ดังนี้:
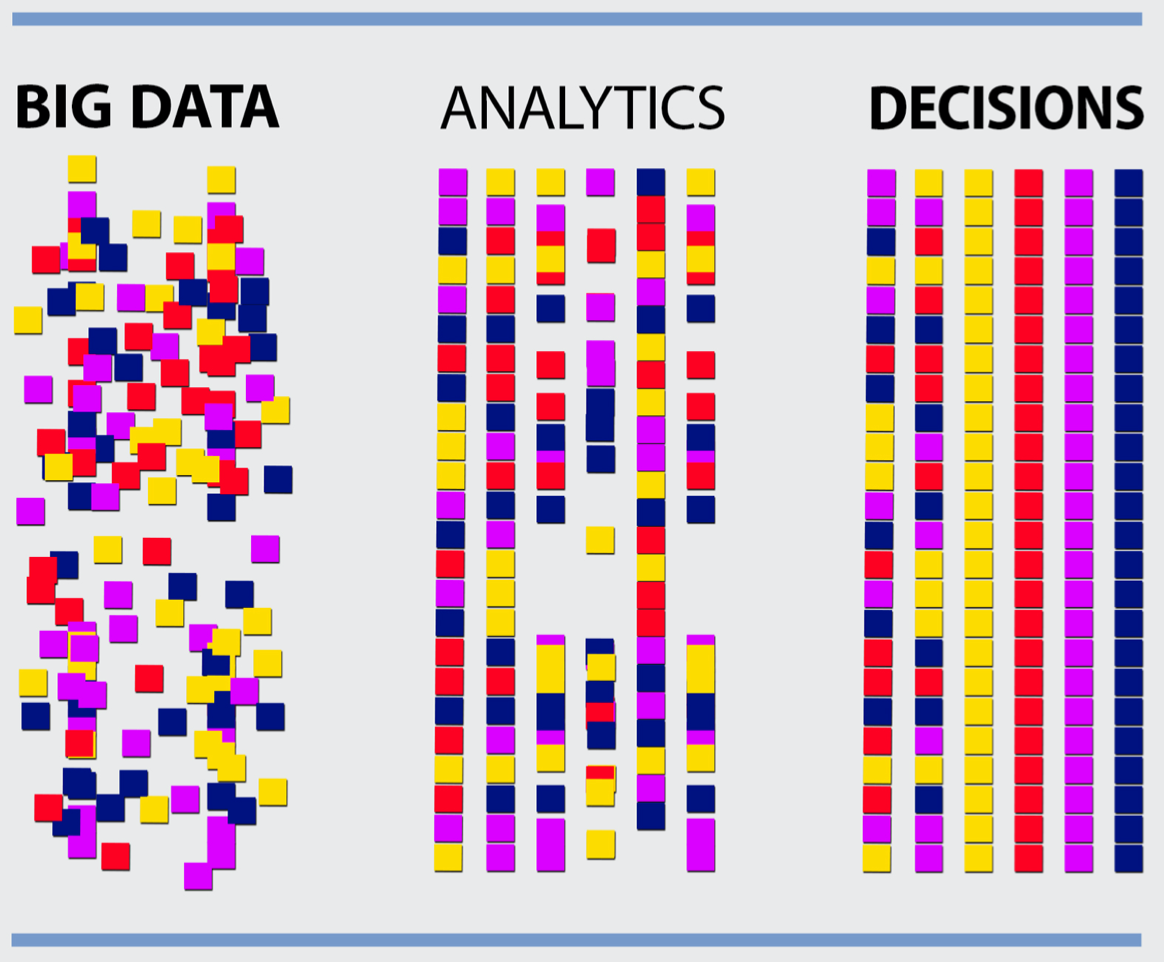
ข้อมูล (Data): คือหน่วยที่เล็กที่สุดของข้อเท็จจริงที่ยังไม่ผ่านการจัดระเบียบเช่น ตัวเลขราคาหุ้น ปริมาณสินค้าคงคลัง หรือพิกัดตำแหน่งของผู้ใช้งาน ในขั้นนี้ข้อมูลยังไม่สามารถบอกทิศทางหรือความหมายใด ๆ ได้ จนกว่าจะถูกนำเข้าสู่กระบวนการวิเคราะห์
สารสนเทศ (Information): เกิดจากการนำข้อมูลดิบมาผ่านกระบวนการจัดการ เช่น การจัดกลุ่ม การเปรียบเทียบ หรือการสรุปผล เพื่อตอบคำถามพื้นฐานว่า “เกิดอะไรขึ้น” เช่น การสรุปยอดขายประจำเดือน หรือการคำนวณอัตราการเติบโตของยอดผู้ใช้งาน
ความเข้าใจเชิงลึก (Insight): คือการนำสารสนเทศมาวิเคราะห์หาความสัมพันธ์เชิงลึกเพื่อตอบคำถามว่า “ทำไมสิ่งนี้ถึงเกิดขึ้น” ในขั้นนี้จะเริ่มเห็น โครงสร้างของข้อมูล เช่น การพบว่ายอดขายกาแฟเพิ่มขึ้นอย่างมีนัยสำคัญในช่วงที่มีฝนตก หรือความสัมพันธ์ระหว่างโปรโมชั่นกับพฤติกรรมการซื้อซ้ำของลูกค้า
การตัดสินใจ (Decision): คือเป้าหมายสูงสุดของกระบวนการ เมื่อเรามีความเข้าใจเชิงลึกที่ชัดเจนเพียงพอ จะนำไปสู่การกำหนดทิศทางหรือเลือกทางเลือกที่ดีที่สุดเพื่อลดความเสี่ยงและสร้างโอกาสทางธุรกิจ โดยมีหลักฐานเชิงประจักษ์รองรับแทนการใช้สัญชาตญาณ [1]
2.2 รายละเอียดประเภทของข้อมูลตามโครงสร้าง
การเข้าใจโครงสร้างของข้อมูลเป็นจุดเริ่มต้นสำคัญก่อนนำข้อมูลไปวิเคราะห์ เนื่องจากวิธีในการจัดเก็บและการประมวลผลข้อมูล จะแตกต่างกันไปตามลักษณะของข้อมูล ดังนี้
ข้อมูลเชิงโครงสร้าง (Structured Data): เป็นข้อมูลที่ผ่านการนิยามรูปแบบมาอย่างชัดเจนก่อนการจัดเก็บ มักอยู่ในรูปแบบตัวเลขหรือข้อความสั้นๆ ที่เป็นระเบียบ ข้อดีคือมีความรวดเร็วสูงในการค้นหาและวิเคราะห์ด้วยอัลกอริทึมทางสถิติและคณิตศาสตร์ เช่น ข้อมูลธุรกรรมทางการเงิน, ข้อมูลรายชื่อนักศึกษา และข้อมูลสต็อกสินค้า
ข้อมูลที่ไม่มีโครงสร้าง (Unstructured Data): เป็นกลุ่มข้อมูลที่มีปริมาณมหาศาลที่สุดในนิเวศวิทยาของข้อมูลขนาดใหญ่ (ประมาณ 80% ของข้อมูลทั้งหมด) เช่น ข้อความอีเมล, รีวิวลูกค้า, รูปภาพสินค้า, ไฟล์วิดีโอ และเสียงบันทึก เป็นต้น ข้อมูลเหล่านี้ไม่สามารถจัดเก็บในตารางปกติได้เนื่องจากมีความซับซ้อนสูง การวิเคราะห์จำเป็นต้องใช้เทคโนโลยีขั้นสูงเข้ามาช่วย เช่น การใช้การประมวลภาษาธรรมชาติ (NLP) เพื่อวิเคราะห์ความหมายในอีเมล หรือการใช้ คอมพิวเตอร์วิทัศน์ (Computer Vision) เพื่อจำแนกวัตถุในรูปภาพสินค้า [2]
ข้อมูลกึ่งโครงสร้าง (Semi-Structured Data): ทำหน้าที่เป็นสะพานเชื่อมระหว่างข้อมูลสองประเภทข้างต้น แม้จะไม่มีรูปแบบตารางที่ตายตัว แต่มีการใช้ แท็ก (Tags) หรือ คีย์ (Keys) เพื่อระบุความหมายของข้อมูลแต่ละส่วน เช่น ข้อมูลจากเซนเซอร์ IoT หรือข้อมูล JSON ที่ใช้ในการส่งผ่านข้อมูลระหว่างเว็บแอปพลิเคชัน (Web API) ซึ่งช่วยให้ระบบคอมพิวเตอร์สามารถ “อ่าน” และ “แยกแยะ” โครงสร้างข้อมูลได้โดยอัตโนมัติ
ตัวอย่างของแบบกึ่งโครงสร้าง การเก็บข้อมูลด้วย JSON
{
"device_id": "IOT-CMU-001",
"location": "ICDI Coffee Corner",
"timestamp": "2026-05-02T13:45:00Z",
"status": {
"temperature": 92.5,
"water_level": "High",
"is_active": true
},
"recent_orders": [
{ "menu": "Latte", "size": "M" },
{ "menu": "Americano", "size": "L" }
]
}2.2.1 ประเภทของข้อมูลตามลักษณะทางสถิติ
การจำแนกข้อมูลตามมาตรวัด ไม่ได้มีประโยชน์เพียงแค่การจัดหมวดหมู่ แต่เป็นตัวกำหนดว่าเราสามารถใช้ “คณิตศาสตร์” ประเภทใดได้บ้างกับข้อมูลนั้น ๆ เพื่อทำให้ข้อมูลมีโครงสร้างที่ชัดเจน
ข้อมูลเชิงคุณภาพ (Qualitative/Categorical Data) เน้นการจำแนกความแตกต่างเชิงลักษณะ มากกว่าการเปรียบเทียบในเชิง “มากกว่า/น้อยกว่า”
นามบัญญัติ (Nominal Scale): เป็นระดับพื้นฐานที่สุด ใช้เพื่อการระบุชื่อหรือจำแนกกลุ่มเท่านั้น ไม่สามารถนำมาบวก ลบ คูณ หาร หรือเรียงลำดับได้ ในเชิงธุรกิจ เช่น ประเภทสินค้า (กาแฟ ชา ขนมปัง เป็นต้น) หากเราใช้ตัวเลข 1, 2, 3 แทนชื่อกลุ่ม ตัวเลขเหล่านี้เป็นเพียง “สัญลักษณ์” ไม่มีความหมายเชิงปริมาณ
ลำดับขั้น (Ordinal Scale): ข้อมูลมีการจัดลำดับความสำคัญ สามารถบอกได้ว่าสิ่งใดดีกว่าหรือสูงกว่า แต่ไม่สามารถระบุได้ว่าห่างกันเท่าใดในเชิงตัวเลขที่แน่นอน เช่น ระดับความพึงพอใจ (พึงพอใจมาก > พึงพอใจมากที่สุด) สถิติที่นิยมใช้คือ “มัธยฐาน” (Median) มากกว่า “ค่าเฉลี่ย” (Mean)
ข้อมูลเชิงปริมาณ (Quantitative/Numerical Data) เป็นข้อมูลที่ตัวเลขมีความหมายเชิงคณิตศาสตร์อย่างแท้จริง สามารถนำไปคำนวณทางสถิติขั้นสูงได้
แบบไม่ต่อเนื่อง (Discrete Data): ข้อมูลที่มีค่าเป็นจำนวนเต็มเสมอ มักเกิดจากการ “นับ” และมีช่องว่างระหว่างหน่วยข้อมูลที่ชัดเจน เช่น จำนวนผู้โดยสารในเที่ยวบิน หรือจำนวนสาขาของร้านกาแฟ (ไม่มี 1.5 สาขา)
แบบต่อเนื่อง (Continuous Data): ข้อมูลที่มีความละเอียดสูงและสามารถมีค่าทศนิยมได้ไม่จำกัด มักเกิดจากการ “วัด” เช่น อุณหภูมิของเครื่องคั่วกาแฟ หรือรายได้สุทธิของบริษัท ข้อมูลประเภทนี้มีความยืดหยุ่นสูงสุดในการสร้างแบบจำลองทางสถิติและเศรษฐมิติ [3]
2.2.2 แหล่งที่มาของข้อมูลในมิติต่าง ๆ
ในการสร้างแบบจำลองทางธุรกิจที่สามารถทำกำไรได้ดี นักวิเคราะห์จำเป็นต้องบูรณาการข้อมูลจากหลายแหล่งเพื่อให้เห็นภาพรวมที่ชัดเจน โดยแบ่งออกเป็น 3 ระดับหลัก ดังนี้
ข้อมูลระดับจุลภาค (Micro-level Data) เป็นข้อมูลที่สะท้อนถึงพฤติกรรมของหน่วยเศรษฐกิจขนาดเล็กที่สุด ซึ่งเป็นรากฐานของการทำ ระบบธุรกิจอัจฉริยะ (BI):
ข้อมูลองค์กร: มุ่งเน้นไปที่การจัดการภายใน เช่น โครงสร้างต้นทุน อัตราการหมุนเวียนสินค้าคงคลัง และผลผลิตต่อชั่วโมงการทำงาน
ข้อมูลบุคคลและครัวเรือน: ข้อมูลพฤติกรรมการบริโภครายบุคคล ระดับรายได้สุทธิ และทัศนคติต่อผลิตภัณฑ์ ซึ่งช่วยให้ธุรกิจสามารถทำการตลาดส่วนบุคคลได้อย่างแม่นยำ [4]
ความสำคัญ: ช่วยให้ผู้บริหารเข้าใจ “สุขภาพ” ของบริษัทและ “ความต้องการ” ของลูกค้าในระดับรายคน
ข้อมูลระดับมหภาค (Macro-level Data) ข้อมูลที่สะท้อนสภาวะแวดล้อมภายนอกซึ่งส่งผลกระทบต่อทุกธุรกิจในวงกว้าง:
ดัชนีชี้วัดทางเศรษฐกิจ: เช่น อัตราเงินเฟ้อ ที่ส่งผลต่อกำลังซื้อ หรืออัตราการว่างงานที่สะท้อนความเชื่อมั่นของผู้บริโภค
ข้อมูลประชากรและทรัพยากร: สำมะโนประชากรช่วยในการวางแผนขยายสาขา ขณะที่ข้อมูลปริมาณไฟฟ้าและน้ำมันเป็นตัวแปรสำคัญในการพยากรณ์ต้นทุนการขนส่งและการผลิตในระยะยาว
ความสำคัญ: ช่วยให้ธุรกิจสามารถประเมิน ความเสี่ยงเชิงระบบ และปรับกลยุทธ์ให้สอดคล้องกับทิศทางเศรษฐกิจโลก
ข้อมูลทางการเงิน (Financial Data) เป็นข้อมูลที่มีความเคลื่อนไหวรวดเร็ว และมักถูกนำมาใช้ในแบบจำลองทางสถิติเพื่อการคาดการณ์:
ข้อมูลตลาดทุนและสินทรัพย์: ปริมาณการซื้อขาย และความผันผวนของราคา ในตลาดหุ้น ทองคำ หรือคริปโทเคอร์เรนซี บอกถึงมูลค่าสินทรัพย์ และยังถูกใช้เป็น “ดัชนีชี้วัดล่วงหน้า” (Leading Indicators) ของสภาวะเศรษฐกิจในอนาคต
ความสำคัญ: ในโลกของข้อมูลขนาดใหญ่ ข้อมูลทางการเงินถูกนำมาใช้เพื่อบริหารพอร์ตการลงทุนและการป้องกันความเสี่ยง (Hedging) อย่างเป็นระบบ
2.3 กระบวนการจัดการข้อมูล
ในทางปฏิบัติ นักวิเคราะห์ข้อมูลมักใช้เวลากว่า 70-80% ไปกับกระบวนการเตรียมข้อมูล [5] เพื่อให้มั่นใจว่าผลลัพธ์ที่ได้จากแบบจำลองทางสถิติมีความน่าเชื่อถือ โดยมีขั้นตอนสำคัญในกระบวนการการทำงานแบบสายท่อข้อมูล (Data Pipeline) ดังนี้
การจัดเก็บข้อมูล (Data Collection & Ingestion): เริ่มต้นจากการดึงข้อมูลจากแหล่งกำเนิด ไม่ว่าจะเป็นการบันทึกธุรกรรมผ่านระบบ POS, การเก็บ Log การเข้าชมเว็บไซต์ หรือการดึงข้อมูลจาก API ของตลาดการเงิน ข้อมูลในขั้นนี้มักมีความหลากหลายสูง และยังไม่มีความพร้อมสำหรับการวิเคราะห์
การทำความสะอาดข้อมูล (Data Cleaning & Scrubbing): คือกระบวนการจัดการกับข้อมูลที่ไม่สมบูรณ์ ได้แก่
Handling Missing Values: การตัดสินใจว่าจะ “ลบ” หรือ “เติม” (Impute) ข้อมูลที่ขาดหายไป
Removing Outliers: การคัดกรองข้อมูลที่ผิดปกติเกินจริงซึ่งอาจเกิดจากความผิดพลาดของระบบ
Standardization: การจัดรูปแบบให้เป็นมาตรฐานเดียวกัน เช่น รูปแบบวันที่ (DD/MM/YYYY) หรือหน่วยวัดต่าง ๆ เพื่อความง่ายต่อการนำไปวิเคราะห์
การปรับเปลี่ยนรูปทรงข้อมูล (Data Reshaping & Flattening): ข้อมูลที่ไม่มีโครงสร้างหรือกึ่งโครงสร้าง (เช่น JSON หรือ XML) ต้องได้รับการ “คลี่” (Flattening) ให้อยู่ในรูปตาราง เพื่อให้ซอฟต์แวร์ทางสถิติอย่าง R หรือ Python สามารถประมวลผลได้ นอกจากนี้ยังรวมถึงการเปลี่ยนรูปแบบตารางจากแบบกว้าง (Wide format) เป็นแบบยาว (Long format) เพื่อให้เหมาะสมกับเทคนิคการวิเคราะห์นั้น ๆ
การสกัดคุณลักษณะ (Feature Extraction & Engineering): เป็นขั้นตอนระดับสูงในการเปลี่ยนข้อมูลดิบให้เป็นตัวแปรที่มีความหมายเชิงสถิติ เช่น
ข้อมูลภาพ (Image Data): การแปลงพิกเซลของรูปภาพตัวเลขเขียนมือ (MNIST) ให้กลายเป็นเวกเตอร์ตัวเลขเพื่อใช้ในการเรียนรู้ของเครื่อง
ข้อมูลข้อความ (Text Data): การแปลงประโยคจากรีวิวลูกค้าให้กลายเป็นคะแนนความรู้สึก (Sentiment Score) [6]
ข้อมูลอนุกรมเวลา(Time Series): การสกัด “วันในสัปดาห์” หรือ “ช่วงเวลาของวัน” จากตราเวลา (Timestamp) เพื่อหาพฤติกรรมการซื้อของผู้บริโภค

จากภาพ Figure 2.1 ที่รวมเหล่าตัวละครยอดนิยม สามารถสกัดข้อมูล (Feature Extraction) ออกมาเป็น ข้อมูลเชิงโครงสร้างเบื้องต้นได้เป็น Table 2.2 ดังนี้
| Character Name | Movie/Series | Character Type | Gender | Species | Costume Color | Is Human (Yes/No) |
|---|---|---|---|---|---|---|
| Woody | Toy Story | Protagonist | Male | Toy (Cowboy) | Yellow/Brown | No |
| Buzz Lightyear | Toy Story | Protagonist | Male | Toy (Space Ranger) | White/Green | No |
| Elsa | Frozen | Protagonist | Female | Human (Magical) | Light Blue | Yes |
| Sulley | Monsters, Inc. | Protagonist | Male | Monster | Blue/Purple | No |
| Remy | Ratatouille | Protagonist | Male | Rat | Grey (Chef Hat) | No |
| Nemo | Finding Nemo | Protagonist | Male | Clownfish | Orange/White | No |
| Joy | Inside Out | Protagonist | Female | Emotion | Yellow/Green | No |
2.4 คุณภาพของข้อมูล: ปัจจัยชี้ขาดความสำเร็จของธุรกิจยุคดิจิทัล
ในยุคข้อมูลขนาดใหญ่ “ปริมาณ” ของข้อมูลอาจไม่มีค่าเลยหากขาด “คุณภาพ” การตัดสินใจบนข้อมูลที่ไร้คุณภาพทำให้เสียโอกาสและอาจนำไปสู่ความเสียหายเชิงกลยุทธ์ องค์ประกอบของข้อมูลที่ดี มี 4 มิติหลักดังนี้
ความถูกต้อง (Accuracy)
คำอธิบาย: ข้อมูลต้องตรงกับข้อเท็จจริงหรือเหตุการณ์ที่เกิดขึ้นจริงโดยไม่มีความคลาดเคลื่อน
นัยสำคัญต่อธุรกิจ: หากข้อมูลยอดขายในระบบ POS บันทึกค่าผิดพลาด แบบจำลองการพยากรณ์ยอดขาย จะบิดเบือนทันที นำไปสู่การสั่งซื้อวัตถุดิบที่มากหรือน้อยเกินไป [7]
หัวใจสำคัญ: “Garbage In, Garbage Out” (GIGO) — หากจุดเริ่มต้นผิด ผลลัพธ์ย่อมผิด
ความครบถ้วน (Completeness)
คำอธิบาย: ข้อมูลต้องมีรายละเอียดครบทุกมิติที่จำเป็นต่อการตัดสินใจ ไม่มีช่องว่าง (Missing Values) ในส่วนที่เป็นนัยสำคัญ
นัยสำคัญต่อธุรกิจ: การวิเคราะห์พฤติกรรมลูกค้าที่มีเพียง “ยอดซื้อ” แต่ขาด “พิกัดที่ตั้ง” หรือ “เวลาที่ซื้อ” จะทำให้ธุรกิจไม่สามารถทำการวิเคราะห์เชิงพื้นที่ทางภูมิศาสตร์ เพื่อหาทำเลที่ตั้งร้านกาแฟใหม่ได้อย่างแม่นยำ
ความสอดคล้อง (Consistency)
คำอธิบาย: ข้อมูลเรื่องเดียวกันที่จัดเก็บในต่างระบบหรือต่างแผนก ต้องมีค่าที่ตรงกันและไม่ขัดแย้งกัน
นัยสำคัญต่อธุรกิจ: หากฝ่ายการตลาดระบุว่าลูกค้า A เป็น “ระดับ Gold” แต่ฝ่ายบัญชีระบุว่าเป็น “ระดับ Silver” จะทำให้เกิดความสับสนในการมอบสิทธิประโยชน์ (Service Failure) การสร้างแหล่งเดียวของความจริง (Single Source of Truth) จึงเป็นเรื่องสำคัญในระบบการทำงานผ่านท่อของข้อมูล
ความทันเวลา (Timeliness)
คำอธิบาย: ข้อมูลต้องมีความสดใหม่ และถูกประมวลผลให้พร้อมใช้งานในเวลาที่ต้องการ
นัยสำคัญต่อธุรกิจ: ในโลกของข้อมูลความถี่สูง (High-frequency Data) เช่น ราคาหุ้นหรือเทรนด์ในโซเชียลมีเดีย ข้อมูลที่ล่าช้าเพียงไม่กี่นาทีอาจหมดมูลค่าไปทันที ข้อมูลที่ดีต้องสนับสนุนการตัดสินใจได้แบบทันที
“การวิเคราะห์ข้อมูลขนาดใหญ่ ไม่ได้เริ่มที่การใช้ขั้นตอนวิธี (Algorithm) ที่ซับซ้อนที่สุด แต่เริ่มที่การตรวจสอบว่าข้อมูลในมือเรานั้น ‘เชื่อถือได้’ มากแค่ไหน”
2.5 แบบฝึกหัดท้ายบท: การจัดการข้อมูลและการคิดเชิงวิเคราะห์
การเปลี่ยนรูปข้อมูล: จงอธิบายความแตกต่างระหว่างข้อมูล (Data) และสารสนเทศ (Information) โดยใช้กรณีศึกษาร้านกาแฟ (เช่น ข้อมูลดิบจากใบเสร็จ 1,000 ใบ เปลี่ยนเป็นสารสนเทศที่บอกว่า “เมนูใดขายดีที่สุดในช่วงบ่าย” ได้อย่างไร)
การจำแนกมาตรวัดทางสถิติ: จงระบุประเภทของข้อมูล (Nominal, Ordinal, Discrete หรือ Continuous) ของตัวแปรต่อไปนี้ พร้อมให้เหตุผลประกอบสั้นๆ:
ยอดขายรายวัน (หน่วย: บาท)
ระดับความพึงพอใจลูกค้า (ดีมาก, ดี, พอใช้)
หมายเลขสมาชิกบัตรสะสมแต้ม
อุณหภูมิภายในถังเก็บน้ำนม (หน่วย: องศาเซลเซียส)
จำนวนพนักงานที่เข้ากะในแต่ละวัน
ความยืดหยุ่นของข้อมูล: ข้อมูลกึ่งโครงสร้าง (Semi-Structured) เช่น JSON มีข้อดีเหนือกว่าข้อมูลเชิงโครงสร้าง (ตาราง SQL) อย่างไร ในบริบทของการเก็บข้อมูลจากเซนเซอร์ IoT ที่อาจมีการเพิ่มฟีเจอร์ใหม่ๆ ในอนาคต
การเชื่อมโยงข้อมูลหลายระดับ: หากคุณเป็นเจ้าของธุรกิจอสังหาริมทรัพย์ จงยกตัวอย่างข้อมูล ระดับมหภาคและ ระดับจุลภาค อย่างละ 2 รายการที่คุณต้องนำมาวิเคราะห์ร่วมกันก่อนตัดสินใจลงทุนโครงการใหม่
กระบวนการทำงานผ่านท่อของข้อมูล: ในขั้นตอนการทำความสะอาดข้อมูล หากนักศึกษาพบว่าข้อมูล “รายได้ลูกค้า” มีค่าที่หายไป (Missing Value) ประมาณ 5% นักศึกษาจะมีแนวทางจัดการอย่างไรเพื่อให้ข้อมูลนั้นยังคงคุณภาพ (Accuracy) ก่อนนำไปวิเคราะห์ต่อ
จริยธรรมและจรรยาบรรณ: (ข้อเพิ่มเติม) จากกรณีศึกษาการสกัดข้อมูลจากรูปภาพ เช่น การใช้ใบหน้าลูกค้าเพื่อวิเคราะห์อารมณ์ในร้านค้า นักศึกษาคิดว่ามีประเด็นด้านจริยธรรมข้อมูล (Data Ethics) หรือความเป็นส่วนตัว (PDPA) ใดบ้างที่ต้องระมัดระวัง [8]
การคิดเชิงระบบ (Systematic Thinking): วิเคราะห์ผลกระทบที่จะเกิดขึ้นต่อ “ความน่าเชื่อถือขององค์กร” หากผู้บริหารตัดสินใจเลือกทำเลที่ตั้งสาขาใหม่โดยใช้ข้อมูลที่มีความไม่ต้องกัน (Inconsistency) (ข้อมูลจากฝ่ายการตลาดและฝ่ายสำรวจทำเลไม่ตรงกัน)