3 จากปัญหาทางธุรกิจสู่ปัญหาทางข้อมูล
3.1 การตั้งคำถาม: สะพานเชื่อมระหว่างโลกธุรกิจและโลกข้อมูล
การตั้งคำถามที่ถูกต้อง คือการกำหนดทิศทางของความชัดเจนดชิงโครงสร้าง ตั้งแต่ต้นน้ำ ในบริบทของข้อมูลขนาดใหญ่ คำถามที่ดีต้องไม่ใช่แค่คำถามเชิงพรรณนาว่า “เกิดอะไรขึ้น” (Descriptive) แต่ต้องนำไปสู่การตั้งสมมติฐานเพื่อหา “ความสัมพันธ์เชิงสาเหตุ” (Causal Relationship) หรือ “การพยากรณ์” (Prediction) ที่แม่นยำ
ทำไมการตั้งคำถามจึงสำคัญกว่าอัลกอริทึม? ในปัจจุบันนี้เรามีเครื่องมือ AI และระบบประมวลผลความเร็วสูง ความท้าทายไม่ได้อยู่ที่การ “หาคำตอบ” แต่อยู่ที่การ “นิยามโจทย์” หากคำถามตั้งอยู่บนสมมติฐานที่ผิด (Spurious Correlation) ผลลัพธ์ที่ได้จะเป็นเพียงตัวเลขที่ดูน่าสนใจแต่ไร้คุณค่าทางกลยุทธ์ เช่น การพบว่ายอดขายไอศกรีมสัมพันธ์กับจำนวนเหตุไฟไหม้ ซึ่งคำถามที่ถูกต้องควรจะมองไปที่ตัวแปรแฝง (Latent Variable) อย่าง “อุณหภูมิที่เพิ่มขึ้น” เป็นต้น
พลังของข้อมูลขนาดใหญ่ และหลักการทางสถิติ เมื่อเราขยับจากการใช้ข้อมูลกลุ่มตัวอย่าง มาเป็นการใช้ข้อมูลขนาดใหญ่ ที่ครอบคลุมประชากรเกือบทั้งหมด หลักการทางสถิติจะกลายเป็น “เกราะป้องกัน” การตัดสินใจที่ผิดพลาด [1]
3.1.1 กฎจำนวนมากในบริบทธุรกิจ
กฎจำนวนมาก (Law of Large Numbers - LLN) ไม่ได้เป็นเพียงทฤษฎีในห้องเรียนสถิติ แต่เป็น “เข็มทิศเชิงยุทธศาสตร์” ที่เปลี่ยนความเสี่ยง (Risk) ให้กลายเป็นความน่าจะเป็นที่จัดการได้
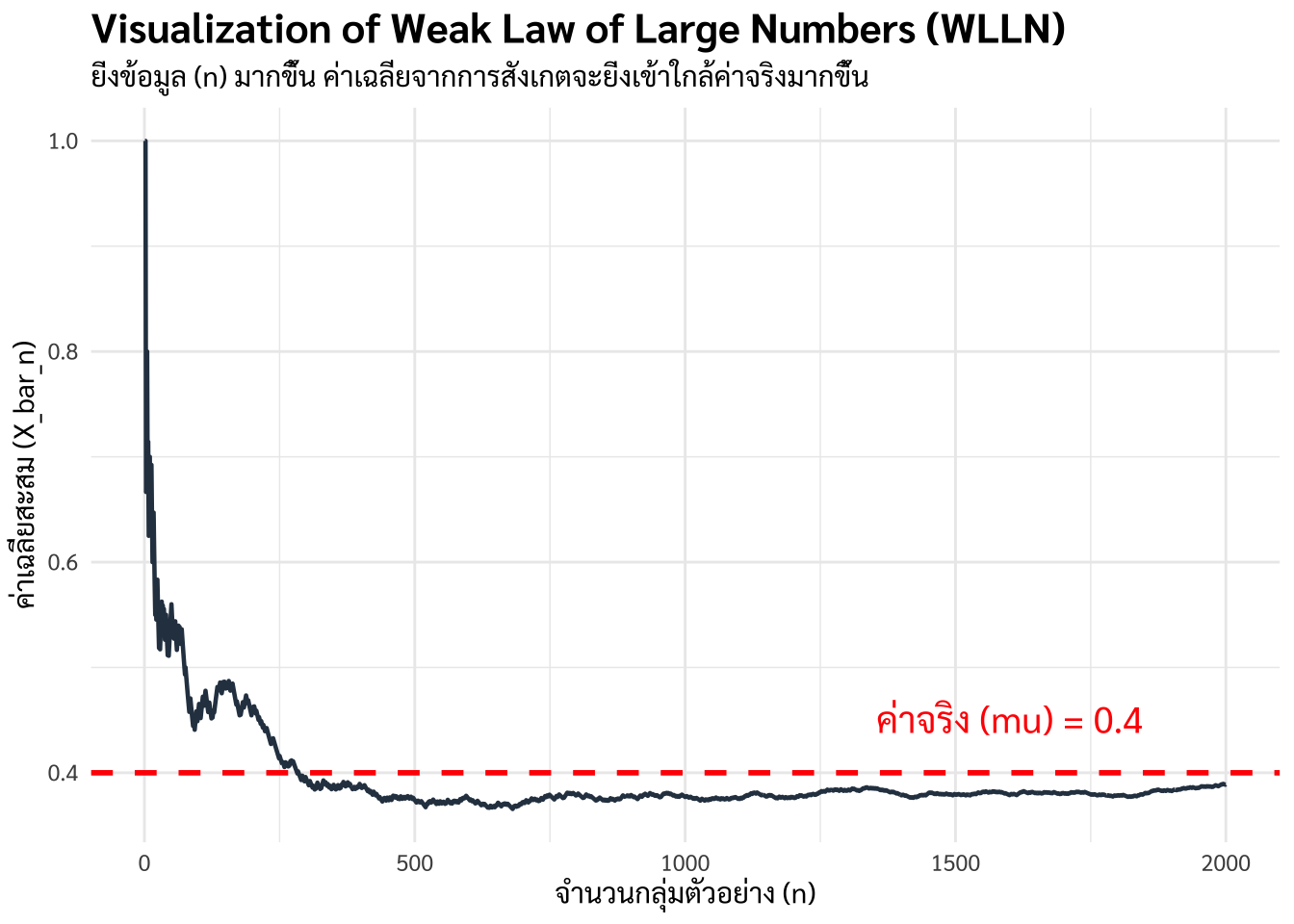
การกำจัดสิ่งรบกวน (Noise) เพื่อหาสัญญาณ (Signal) ในข้อมูลขนาดเล็ก ความผันผวนชั่วคราวหรือสิ่งรบกวน เช่น ลูกค้าคนหนึ่งอารมณ์เสียแล้วให้คะแนนร้านต่ำมาก อาจทำให้ค่าเฉลี่ยความพึงพอใจบิดเบือนไปจากความจริง แต่ในโลกของข้อมูลขนาดใหญ่ เมื่อ \(n\) มีค่ามหาศาล พฤติกรรมที่ผิดปกติเหล่านี้จะถูก “เฉลี่ย” ออกไป จนเหลือเพียงสัญญาณ หรือแนวโน้มพฤติกรรมที่แท้จริงของตลาด [2]
ความเสถียรของการพยากรณ์ บริษัทอย่าง Amazon หรือ Netflix ใช้ LLN เป็นรากฐานในการลงทุน
Amazon: กล้าสต็อกสินค้าล่วงหน้าในคลังสินค้าใกล้ตัวคุณ เพราะเมื่อวิเคราะห์จากธุรกรรมนับล้าน ค่าเฉลี่ยความต้องการสินค้า จะมีความแม่นยำสูงมากจนความเสี่ยงในการสต็อกของเหลือค้างมีต่ำ
Netflix: กล้าทุ่มงบสร้างซีรีส์มูลค่าหลายพันล้าน เพราะรู้ว่าค่าเฉลี่ยความชื่นชอบของผู้ชมในฐานข้อมูลขนาดมหึมานั้นเสถียรพอที่จะยืนยันได้ว่าคอนเทนต์ประเภทนี้จะมีผู้ดูแน่นอน [3]
การเปลี่ยนความเชื่อเป็นหลักฐานเชิงประจักษ์ LLN ช่วยให้นักบริหารเปลี่ยนจากการใช้ “สัญชาตญาณ” (Intuition) มาเป็น “การตัดสินใจตามหลักฐาน” เพราะทฤษฎียืนยันว่า ยิ่งเราขยายฐานข้อมูลให้กว้างขึ้น เรายิ่งเข้าใกล้โครงสร้างความจริงของตลาดมากขึ้นตามทฤษฎี
จาก Figure 3.1 การเปรียบเทียบผลกระทบของสิ่งรบกวน ในข้อมูลขนาดเล็ก (ขวา) เทียบกับสัญญาณ ในข้อมูลขนาดใหญ่ (ซ้าย) ผ่านกฎจำนวนมาก: จะสังเกตได้ว่าความผันผวนของการประมาณค่าพฤติกรรมลูกค้าจะลดลงจนเหลือน้อยมากเมื่อองค์กรจัดเก็บข้อมูลที่มีปริมาณมากพอ
3.1.2 ทฤษฎีบทหลักพื้นฐานทางสถิติ (First Fundamental Theorem of Statistics)
หาก Law of Large Numbers (LLN) บอกเราว่า “ค่าเฉลี่ย” จะเข้าสู่ความจริง ทฤษฎี Glivenko-Cantelli นี้จะยกระดับขึ้นไปอีกขั้น โดยบอกว่า “โครงสร้างการกระจายตัวทั้งหมด” ของข้อมูลที่เราสังเกตได้ (Empirical Distribution) จะเข้าใกล้โครงสร้างความจริงของประชากร (Theoretical Distribution) เมื่อมีข้อมูลมากพอ
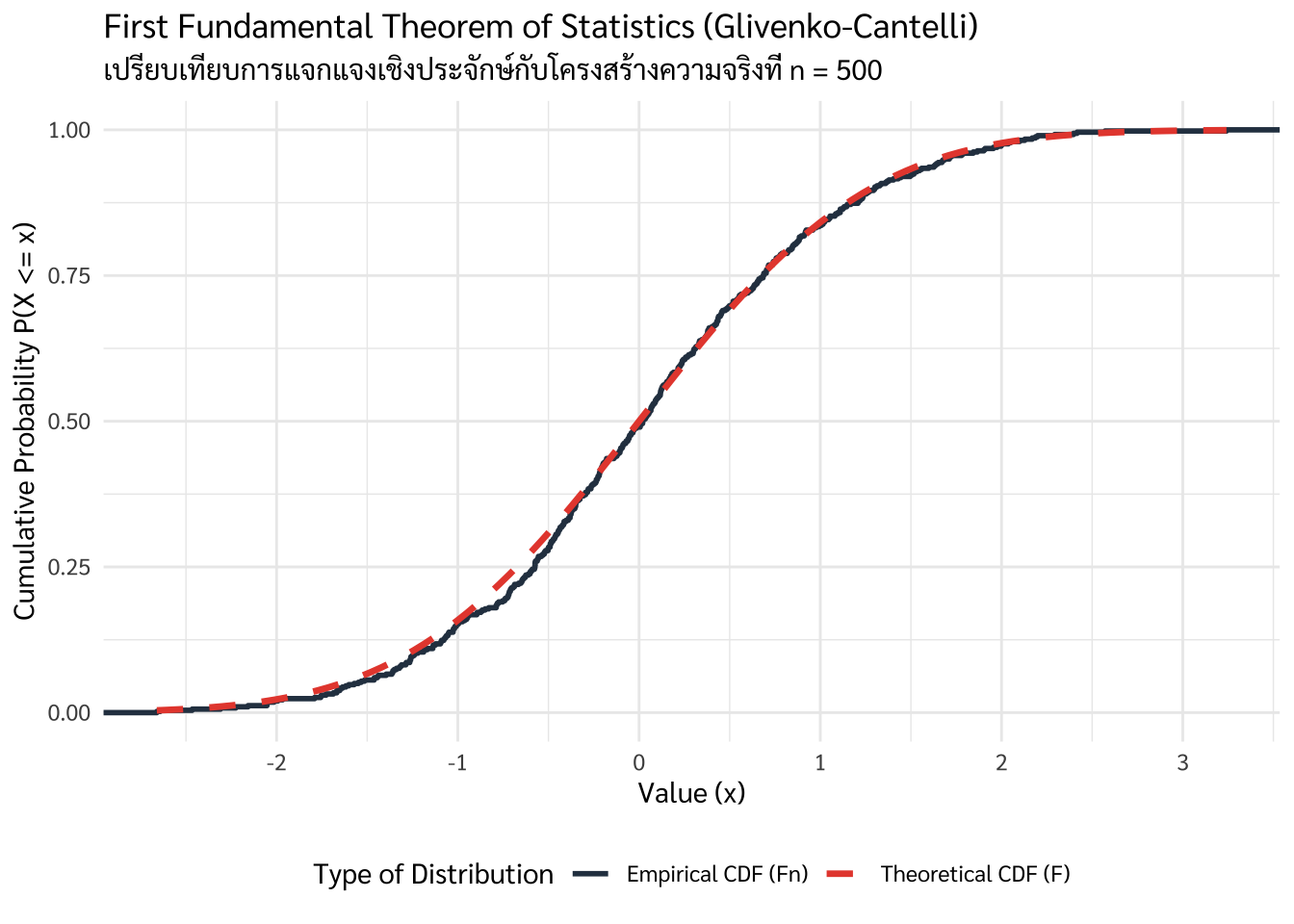
จาก Figure 3.2 การลู่เข้าของฟังก์ชันการแจกแจงสะสมเชิงประจักษ์ (\(F_n\)) เข้าสู่ฟังก์ชันการแจกแจงสะสมทางทฤษฎี (\(F\)) ตามทฤษฎีบทของ Glivenko-Cantelli ที่ระดับ \(n=500\) ซึ่งพิสูจน์ให้เห็นถึงความสามารถของ Big Data ในการจำลองโครงสร้างความจริงของประชากรโดยปราศจากอคติ
3.1.2.1 ความหมายเชิงธุรกิจ
ความแม่นยำของรูปทรงข้อมูล: ไม่ใช่แค่ค่าเฉลี่ยที่ตรง แต่ “สัดส่วน” ของลูกค้ากลุ่มต่าง ๆ ในข้อมูลขนาดใหญ่ จะสะท้อนสัดส่วนที่แท้จริงในตลาด เช่น หากเรามีข้อมูลลูกค้ามากพอ เราจะเห็นสัดส่วนคนชอบดื่มลาเต้เทียบกับอเมริกาโน่ที่แม่นยำจนเกือบ 100%
การลดความผิดพลาดในการคาดการณ์: เมื่อ \(F_n\) ลู่เข้าหา \(F\) หมายความว่าความเสี่ยงที่เราจะ “มองภาพตลาดผิดเพี้ยนไป” จะลดลงจนเป็นศูนย์เมื่อเราขยายขนาดข้อมูล (n) ให้ใหญ่ขึ้น
รากฐานของการพิเคราะห์เชิงทำนาย (Predictive Analytics): ทฤษฎีนี้คือเหตุผลที่ทำให้เราสามารถใช้ข้อมูลในอดีต (Empirical) มาสร้างแบบจำลองเพื่อทำนายอนาคต (Theoretical) ได้อย่างมั่นใจ [4]
“ในโลกของข้อมูลขนาดใหญ่ เราไม่ได้แค่สุ่มตรวจเพื่อหาค่าเฉลี่ย แต่เรากำลังพยายาม ‘จำลองโครงสร้างความจริง’ (\(F\)) ผ่านข้อมูลมหาศาลที่เราจัดเก็บ (\(F_n\)) ซึ่งทฤษฎีทางสถิตินี้ยืนยันว่า ยิ่งเราจัดการข้อมูลให้มีคุณภาพและมีปริมาณมากพอ โครงสร้างที่เราสร้างขึ้นจะสะท้อนความจริงของธุรกิจได้โดยปราศจากอคติ”
3.2 การแปลงปัญหาทางธุรกิจสู่ปัญหาทางข้อมูล
ในนิเวศวิทยาของข้อมูลขนาดใหญ่ ขั้นตอนที่ท้าทายที่สุดไม่ใช่การประมวลผล แต่คือการ “แปลโจทย์” ปัญหาทางธุรกิจ ซึ่งมักจะเป็นคำถามเชิงกลยุทธ์ที่กว้างและเน้นผลลัพธ์ ให้กลายเป็นปัญหาทางข้อมูล ที่สามารถนิยามด้วยตัวแปร (Variables) และแบบจำลองทางสถิติ (Statistical Models) ได้
การแปลงโจทย์ที่ถูกต้องจะช่วยสร้าง โครงสร้างที่ชัดเจน ทำให้นักวิเคราะห์ทราบว่าต้องใช้ข้อมูลใด และต้องใช้เทคนิคการประมวลผลแบบใดจึงจะตอบโจทย์ธุรกิจได้อย่างแม่นยำ [5] Table 3.1 แสดงตัวอย่างปัญหาและการแก้ไขทางธุรกิจด้วยวิทยาการข้อมูล
| ปัญหาทางธุรกิจ | ปัญหาทางข้อมูล | เทคนิคและโมเดลที่เกี่ยวข้อง | เป้าหมายเชิงกลยุทธ์ |
|---|---|---|---|
| ยอดขายตกต่ำลงอย่างผิดปกติ | ปัจจัยตัวแปรใด (Drivers) ที่ส่งผลต่อการเปลี่ยนแปลงของยอดขายอย่างมีนัยสำคัญ | Regression Analysis / Time Series Analysis | เพื่อระบุสาเหตุที่แท้จริงและปรับปรุงกลยุทธ์การขาย |
| ลูกค้าลดการใช้บริการ (Churn) | ความน่าจะเป็น (Probability) ที่ลูกค้าแต่ละรายจะเลิกใช้บริการภายใน 30 วันข้างหน้า | Classification / Logistic Regression | เพื่อทำแคมเปญรักษาฐานลูกค้า (Retention) ได้ทันเวลา |
| ต้องการเพิ่มยอดขายต่อหัว | สินค้าคู่ใดที่มีความสัมพันธ์กัน (Association) หรือลูกค้ารายนี้ควรได้รับข้อเสนอใด | Recommendation System / Association Rules | การทำ Cross-selling และ Up-selling แบบเฉพาะบุคคล |
| งบประมาณการตลาดไม่พุ่งเป้า | การจัดกลุ่มลูกค้า (Segmentation) ตามพฤติกรรมที่มีลักษณะคล้ายคลึงกัน | Clustering (Unsupervised Learning) | เพื่อทำ Targeted Marketing ให้ตรงกลุ่มเป้าหมาย |
3.2.1 กรณีศึกษา: การแปลงปัญหาของร้าน “Digital Cafe”
สมมติว่ามีผู้ปกครองนักศึกษาเป็นเจ้าของร้านกาแฟที่เก็บข้อมูลผ่านระบบ POS และแอปพลิเคชันสมาชิกอยู่แล้ว แต่พบว่าผลประกอบการเริ่มไม่เป็นไปตามเป้า เราจะแปลงปัญหาเหล่านั้นให้เป็นงานวิเคราะห์ข้อมูลได้อย่างไร?
เมื่อยอดขายช่วงบ่ายหายไป
ปัญหาทางธุรกิจ: “ทำไมยอดขายหลัง 14.00 น. ถึงลดลงอย่างมากเมื่อเทียบกับปีที่แล้ว?”
การแปลงเป็นปัญหาทางข้อมูล: การวิเคราะห์ความสัมพันธ์ (Correlation) ระหว่าง เวลาที่ซื้อ (Timestamp) กับ ปัจจัยภายนอก เช่น อุณหภูมิหรือสภาพอากาศในวันนั้น รวมถึงการเปรียบเทียบประเภทเมนูที่ขายได้ (Hot vs. Iced) เพื่อดูว่าพฤติกรรมลูกค้าเปลี่ยนไปตามสภาพแวดล้อมหรือไม่
การรักษาลูกค้าขาประจำ
ปัญหาทางธุรกิจ: “จะทำอย่างไรให้ลูกค้าที่เคยมาบ่อย ๆ ไม่หายหน้าไป?”
การแปลงเป็นปัญหาทางข้อมูล: การสร้าง Churn Prediction Model โดยนิยามว่าลูกค้าที่ “หายไป” คือผู้ที่ไม่มาใช้บริการเกิน 14 วัน จากนั้นสกัดฟีเจอร์ (Feature Extraction) จากประวัติการสั่งซื้อ (เช่น ความถี่, ยอดใช้จ่ายเฉลี่ย) เพื่อทำนายว่าลูกค้าคนใดมีโอกาสจะหายไปในสัปดาห์หน้า และส่งคูปองส่วนลดไปให้ได้ทันเวลา
การจัดเซตเมนูเพิ่มกำไร
ปัญหาทางธุรกิจ: “ควรจัดโปรโมชั่นจับคู่สินค้า (Combo Set) อย่างไรให้ลูกค้าจ่ายเงินเพิ่มขึ้น?”
การแปลงเป็นปัญหาทางข้อมูล: การวิเคราะห์ตะกร้าสินค้า (Market Basket Analysis) เพื่อหาความสัมพันธ์ว่าลูกค้าที่ซื้อ “อเมริกาโน่เย็น” มักจะซื้อ “ครัวซองต์อัลมอนด์” คู่กันบ่อยแค่ไหน (Support & Confidence) เพื่อออกแบบโปรโมชั่นที่ตรงใจลูกค้าที่สุด
“ในร้านกาแฟ ข้อมูลดิบ (Unstructured) คือเสียงบ่นของลูกค้าหรือภาพถ่ายเมนูที่ลูกค้าโพสต์ลงโซเชียล แต่พอเราแปลงเป็นปัญหาทางข้อมูล เรากำลังสร้าง ‘โครงสร้าง’ (Structured) ให้มัน เพื่อให้เราคำนวณหาคำตอบออกมาเป็นตัวเลขที่ใช้ตัดสินใจได้จริง”
3.3 คุณลักษณะ 4Vs ของข้อมูลขนาดใหญ่
ในการแปลงปัญหาธุรกิจจากข้อมูลขนาดใหญ่ที่มี นักวิเคราะห์จำเป็นต้องเข้าใจคุณลักษณะพื้นฐาน 4 ประการของข้อมูลขนาดใหญ่ ซึ่งแต่ละมิตินำมาซึ่งโอกาสในการสร้างมูลค่าและข้อจำกัดในการประมวลผลที่แตกต่างกัน ดังนี้
Volume (ปริมาณ)
คำอธิบาย: การเพิ่มขึ้นอย่างทวีคูณของปริมาณข้อมูลที่ถูกสร้างและจัดเก็บในแต่ละวินาที จากระดับ Terabytes สู่ Petabytes
นัยสำคัญเชิงธุรกิจ: ปริมาณข้อมูลที่มหาศาลช่วยให้เกิด การวิเคราะห์ ตามกฎจำนวนมาก (LLN) เพราะยิ่งข้อมูลมาก อคติจากความบังเอิญ (Bias) จะยิ่งลดลง ทำให้เราเห็นภาพรวมของตลาดที่แม่นยำกว่าคู่แข่ง
ตัวอย่าง: ข้อมูลธุรกรรมการซื้อขายย้อนหลัง 10 ปีของห้างสรรพสินค้า ที่ช่วยให้เห็นการเปลี่ยนแปลงพฤติกรรมการบริโภคตามช่วงอายุ
Velocity (ความเร็ว)
คำอธิบาย: ความเร็วในการไหลเวียนของข้อมูล ตั้งแต่การสร้าง การส่งผ่าน ไปจนถึงการประมวลผล
นัยสำคัญเชิงธุรกิจ: ในโลกธุรกิจยุคใหม่ “ข้อมูลที่มีค่าที่สุดคือข้อมูลที่เร็วที่สุด” ความเร็วช่วยให้ธุรกิจสามารถทำการตัดสินใจแบบทันที เช่น การตรวจจับการทุจริตบัตรเครดิต หรือการปรับราคาตั๋วเครื่องบินตามความต้องการ ณ ขณะนั้น
ตัวอย่าง: ระบบจราจรอัจฉริยะที่วิเคราะห์ความหนาแน่นของรถยนต์เพื่อปรับเปลี่ยนสัญญาณไฟจราจรแบบนาทีต่อนาที
Variety (ความหลากหลาย)
คำอธิบาย: ข้อมูลไม่ได้จำกัดอยู่เพียงแค่ตารางตัวเลข (Structured) แต่รวมถึงข้อมูลที่ไม่มีโครงสร้าง (Unstructured) เช่น รูปภาพตัวละคร Figure 2.1, เสียงสนทนา และวิดีโอ
นัยสำคัญเชิงธุรกิจ: ความหลากหลายช่วยให้เราเข้าใจลูกค้าในมิติที่ลึกซึ้งขึ้น เช่น การใช้ NLP เพื่อวิเคราะห์อารมณ์ลูกค้าจากข้อความรีวิว แทนที่จะดูแค่คะแนนดาวเพียงอย่างเดียว
ตัวอย่าง: การนำรูปภาพสินค้าจากโซเชียลมีเดียมาวิเคราะห์เพื่อหาเทรนด์แฟชั่นที่กำลังจะมาถึง [6]
Veracity (ความแม่นยำและความเชื่อถือได้)
คำอธิบาย: คุณภาพและความน่าเชื่อถือของข้อมูล ซึ่งรวมถึงความสอดคล้อง และความถูกต้อง
นัยสำคัญเชิงธุรกิจ: ข้อมูลที่มากและเร็วจะไร้ประโยชน์ทันทีหากขาดความน่าเชื่อถือ มิตินี้เน้นไปที่การทำความสะอาดข้อมูล และการตรวจสอบแหล่งที่มา เพื่อป้องกันปัญหา “Garbage In, Garbage Out” (GIGO)
ตัวอย่าง: การคัดกรอง “รีวิวปลอม” ออกจากระบบก่อนนำไปคำนวณคะแนนความพึงพอใจของร้านค้า
“การจัดการข้อมูลขนาดใหญ่ ไม่ใช่แค่เรื่องของการมีข้อมูลเยอะ แต่คือการบริหารจัดการ ความเร็ว เพื่อนำหน้าคู่แข่ง ใช้ ความหลากหลาย เพื่อเข้าใจลูกค้าให้ลึกกว่าเดิม และรักษา ความเชื่อถือได้ เพื่อให้การตัดสินใจของเราไม่ผิดพลาด”
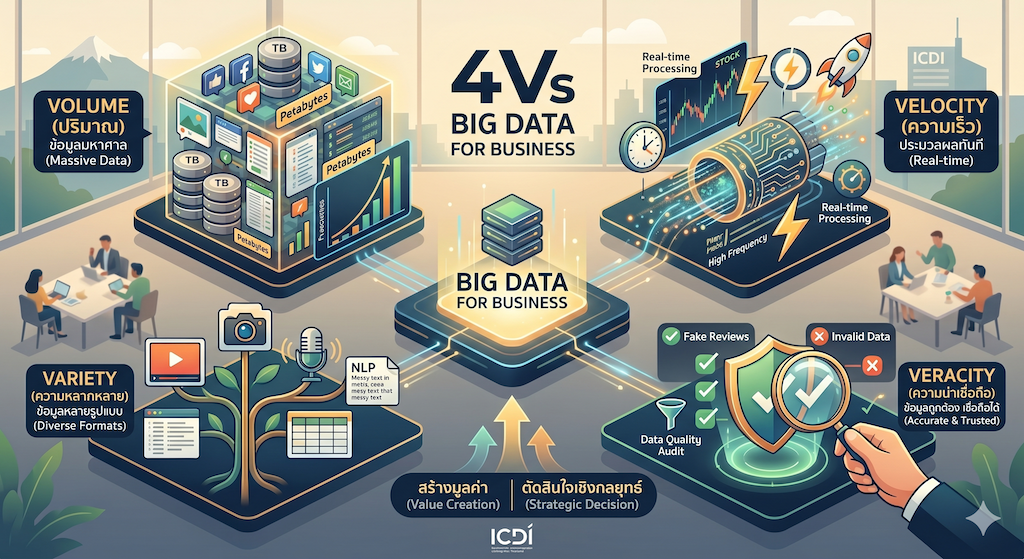
จาก Figure 3.3 อินโฟกราฟิกแสดงคุณลักษณะ 4Vs of Big Data ที่จำเป็นต่อการแปลงปัญหาธุรกิจเป็นปัญหาข้อมูล: Volume (ปริมาณ), Velocity (ความเร็ว), Variety (ความหลากหลาย) และ Veracity (ความน่าเชื่อถือ) เพื่อนำไปสู่การสร้างมูลค่าและการตัดสินใจเชิงกลยุทธ์ตามมโนทัศน์ในนิเวศวิทยาข้อมูล
3.4 แบบจำลองข้อมูลและกลไกการตัดสินใจทางธุรกิจ
ในการเปลี่ยนปัญหาทางข้อมูลให้กลายเป็นมูลค่า นักวิเคราะห์ต้องใช้ แบบจำลอง ซึ่งเปรียบเสมือนเครื่องมือทางคณิตศาสตร์และสถิติที่ใช้ในการอธิบายความสัมพันธ์ระหว่าง ตัวแปรนำเข้า (Input/Predictors) และ ผลลัพธ์ที่คาดหวัง (Output/Outcome) โดยสามารถจำแนกตามวัตถุประสงค์เชิงธุรกิจได้เป็น 4 ประเภทหลัก
การพยากรณ์ (Prediction / Regression)
นิยาม: การใช้ข้อมูลในอดีตเพื่อคาดการณ์ค่าของตัวแปรเชิงปริมาณ (Continuous Data) ในอนาคต
นัยสำคัญเชิงธุรกิจ: ช่วยลดความไม่แน่นอนในการวางแผนทรัพยากร เช่น การพยากรณ์ยอดขายรายวันเพื่อวางแผนการสั่งซื้อวัตถุดิบ หรือการคาดการณ์ราคาหุ้นและสินทรัพย์ดิจิทัลเพื่อการลงทุน
ตัวอย่าง: การใช้แบบจำลองอนุกรมเวลา เพื่อพยากรณ์จำนวนลูกค้าที่จะเข้าร้านในช่วงวันหยุดเทศกาล
การจำแนกประเภท (Classification)
นิยาม: การระบุว่าข้อมูลนั้น ๆ จัดอยู่ในกลุ่มหรือประเภทใด จากตัวเลือกที่กำหนดไว้ล่วงหน้า
นัยสำคัญเชิงธุรกิจ: ช่วยในการคัดกรองและบริหารความเสี่ยง เช่น การตรวจจับธุรกรรมที่ผิดปกติ (Fraud Detection) หรือการระบุกลุ่มลูกค้าที่มีโอกาสจะเลิกใช้บริการ (Churn Prediction) เพื่อยื่นข้อเสนอพิเศษได้ทันท่วงที
ตัวอย่าง: การจำแนกว่าอีเมลฉบับใดเป็น “อีเมลขยะ” หรือการคัดกรองใบสมัครสินเชื่อว่า “ผ่าน” หรือ “ไม่ผ่าน” [7]
การจัดกลุ่มตามพฤติกรรม (Clustering)
นิยาม: การหาโครงสร้างหรือรูปแบบที่ซ่อนอยู่ (Hidden Patterns) โดยไม่มีการกำหนดกลุ่มไว้ล่วงหน้า (Unsupervised Learning)
นัยสำคัญเชิงธุรกิจ: ช่วยในการแบ่งส่วนตลาด (Market Segmentation) เพื่อให้เข้าใจความหลากหลายของลูกค้าได้ลึกซึ้งขึ้น แทนที่จะมองลูกค้าทุกคนเหมือนกันหมด
ตัวอย่าง: การจัดกลุ่มลูกค้าตามพฤติกรรมการซื้อ (เช่น กลุ่มประหยัด, กลุ่มเน้นสินค้าพรีเมียม, กลุ่มซื้อเฉพาะตอนลดราคา) เพื่อทำการตลาดแบบกำหนดเป้าหมาย
การหาค่าที่ดีที่สุด (Optimization)
นิยาม: การคำนวณหาคำตอบที่มีค่าต่ำสุดหรือสูงสุดภายใต้ข้อจำกัด (Constraints) ที่มีอยู่
นัยสำคัญเชิงธุรกิจ: เป็นการเปลี่ยนจากการวิเคราะห์เพื่อ “รู้” เป็นการวิเคราะห์เพื่อ “ลงมือทำ” เช่น การตั้งราคาที่สร้างกำไรสูงสุดโดยที่ลูกค้ายังยอมรับได้ หรือการจัดเส้นทางขนส่งสินค้าที่เสียค่าใช้จ่ายน้อยที่สุด
ตัวอย่าง: การใช้แบบจำลองการกำหนดราคาแบบพลวัต (Dynamic Pricing) สำหรับแพลตฟอร์มเรียกรถหรือที่พัก เพื่อปรับราคาตามความต้องการ ณ ขณะนั้น
“แบบจำลองไม่ใช่ความจริง แต่มันคือโครงสร้างที่เราสร้างขึ้นเพื่อเข้าใกล้ความจริง (\(F_n \to F\)) การเลือกใช้ประเภทของแบบจำลอง ให้ตรงกับปัญหาธุรกิจ จึงเป็นทักษะที่สำคัญที่สุดของนักวิเคราะห์ข้อมูล”
3.5 กระบวนการวิเคราะห์ข้อมูลทางธุรกิจอย่างเป็นระบบ
การแก้ปัญหาด้วยข้อมูลขนาดใหญ่ไม่ใช่กระบวนการที่ทำครั้งเดียวจบ แต่เป็น วงจร (Lifecycle) ที่ต้องอาศัยความสอดคล้องระหว่างกลยุทธ์ทางธุรกิจและเทคนิคทางสถิติ เพื่อสร้างความถูกต้องในการวิเคาะห์ในทุกขั้นตอน ดังนี้
การนิยามปัญหาทางธุรกิจ (Business Understanding)
เป้าหมาย: ระบุวัตถุประสงค์ที่ชัดเจน (Key Objectives) และตัวชี้วัดความสำเร็จ (KPIs)
รายละเอียด: เริ่มต้นจากการตั้งคำถามว่า “เราต้องการแก้ปัญหาอะไร?” เช่น การลดอัตราการเลิกใช้บริการของลูกค้า หรือการลดเวลาในการใช้จัดส่งสินค้า ขั้นตอนนี้ต้องอาศัยความเข้าใจบริบทของอุตสาหกรรมนั้น ๆ เป็นสำคัญ [8]
การแปลงสู่โจทย์ทางข้อมูล (Data Translation)
เป้าหมาย: เปลี่ยนคำถามทางธุรกิจให้เป็นสมมติฐานทางสถิติหรือโจทย์ทางคอมพิวเตอร์
รายละเอียด: ในขั้นตอนนี้เราจะระบุตัวแปรที่เกี่ยวข้อง (Variables) และกำหนดประเภทของปัญหาข้อมูล เช่น เป็นปัญหาการพยากรณ์ (Regression) หรือการจัดกลุ่ม (Clustering) ตามที่เราได้ศึกษาในส่วนก่อนหน้า
การจัดเตรียมข้อมูล (Data Collection & Preparation)
เป้าหมาย: สร้างการทำงานผ่านท่อข้อมูล ที่สะอาดและพร้อมใช้งาน
รายละเอียด: ครอบคลุมการรวบรวมข้อมูลจากแหล่งต่าง ๆ (ETL Process), การทำความสะอาด (Cleaning), และการทำ Feature Engineering เพื่อสกัดลักษณะเด่นที่ส่งผลต่อโมเดล เช่น การแปลงวันเวลาในใบเสร็จให้เป็น “ช่วงเวลาเร่งด่วน” ในร้านกาแฟ
การสร้างและประเมินแบบจำลอง (Modeling & Evaluation)
เป้าหมาย: เลือกอัลกอริทึมที่เหมาะสมและวัดผลความแม่นยำ
รายละเอียด: การฝึกสอนเครื่องจักร (Training) ด้วยข้อมูล และทดสอบด้วยข้อมูลอีกชุดเพื่อประเมินประสิทธิภาพ หากผลลัพธ์ยังไม่น่าพอใจ นักวิเคราะห์ต้องย้อนกลับไปปรับปรุงข้อมูลหรือเปลี่ยนโมเดล (Iterative Process) เพื่อให้เข้าใกล้ความจริงที่สุดตามหลัก \(F_n \to F\)
การตัดสินใจและการนำไปใช้จริง (Deployment & Decision)
เป้าหมาย: เปลี่ยน “ตัวเลข” ให้กลายเป็นการ “ลงมือทำ”
รายละเอียด: นำผลลัพธ์ที่ได้ไปรวมเข้ากับระบบตัดสินใจของธุรกิจ เช่น การใช้ระบบแนะนำสินค้าอัตโนมัติ (Recommendation System) บนหน้าเว็บไซต์ หรือการปรับราคาสินค้าตามความต้องการของตลาด เพื่อสร้างรายได้หรือลดต้นทุนอย่างเป็นรูปธรรม
graph TD
subgraph "Understanding & Planning"
A[Business Problem] --> B[Data Problem]
end
subgraph "Data Engineering"
B --> C[Data Collection]
C --> D[Data Preparation]
end
subgraph "Analytics & Action"
D --> E[Modeling]
E --> F[Evaluation]
F --> G[Decision]
end
%% Iteration Loops
F -.->|Refine Model| E
F -.->|Better Data Needed| D
G -.->|New Insight| A
style A fill:#f9f,stroke:#333,stroke-width:2px
style G fill:#00ff00,stroke:#333,stroke-width:2px
style B fill:#bbf,stroke:#333
style F fill:#ff9,stroke:#333
จากแผนภาพ Figure 3.4 จะเห็นได้ว่าการเปลี่ยนข้อมูลให้กลายเป็นมูลค่าไม่ใช่เส้นตรง แต่เป็นวงจรที่มีความสัมพันธ์ต่อเนื่องกัน
“กระบวนการวิเคราะห์ข้อมูลทางธุรกิจอย่างเป็นระบบไม่ใช่เส้นตรง แต่เป็นวงจรที่ต้องวนซ้ำ หัวใจสำคัญคือ ‘ความสอดคล้อง’ หากขั้นตอนที่ 1 (Business Problem) ผิดพลาด ต่อให้ขั้นตอนที่ 4 (Modeling) จะล้ำสมัยเพียงใด ผลลัพธ์ในขั้นตอนที่ 5 (Decision) ก็จะนำพาองค์กรไปผิดทิศทาง”
นี่คือร่างเนื้อหา (Content) สำหรับหัวข้อนี้ โดยเน้นภาษาที่อ่านง่าย สละสลวย คงความน่าเชื่อถือทางวิชาการ และมุ่งเน้นไปที่ “คุณค่าเชิงธุรกิจ” (Business Capability) ตามแนวคิดที่คุณวางไว้ครับ
3.6 เทคโนโลยีที่เกี่ยวข้องกับข้อมูลขนาดใหญ่
เมื่อองค์กรเข้าใจคุณลักษณะ 4Vs ขอข้อมูลขนาดใหญ่แล้ว คำถามสำคัญในเชิงธุรกิจที่ตามมาคือ “เราจะจัดการกับข้อมูลที่ทั้งใหญ่ หลากหลาย และหลั่งไหลมาอย่างรวดเร็วได้อย่างไรในเมื่อคอมพิวเตอร์แบบดั้งเดิมไม่สามารถรองรับได้อีกต่อไป?”
คำตอบของคำถามนี้ไม่ได้อยู่ที่การซื้อคอมพิวเตอร์ที่เครื่องใหญ่ขึ้นและแพงขึ้น (Vertical Scaling) แต่อยู่ที่การเปลี่ยนวิธีคิดไปสู่ “ระบบประมวลผลแบบกระจาย” (Distributed Computing) และการเลือกใช้เครื่องมือที่เหมาะสมกับลักษณะของข้อมูล
3.6.1 การประมวลผลแบบกระจาย (Distributed Computing)
ในอดีต หากเรามีข้อมูลขนาดใหญ่ล้นธนาคารข้อมูล วิธีแก้ปัญหาคือการอัปเกรดเซิร์ฟเวอร์หลักให้มีแรมและหน่วยความจำสูงขึ้น ซึ่งมีราคาแพงมหาศาลและมีขีดจำกัดทางกายภาพ แต่แนวคิดของ Distributed Computing คือการนำคอมพิวเตอร์ระดับมาตรฐานจำนวนหลายร้อยหลายพันเครื่อง (Nodes) มาเชื่อมต่อกันเป็นเครือข่าย (Cluster) เพื่อช่วยกันทำงาน
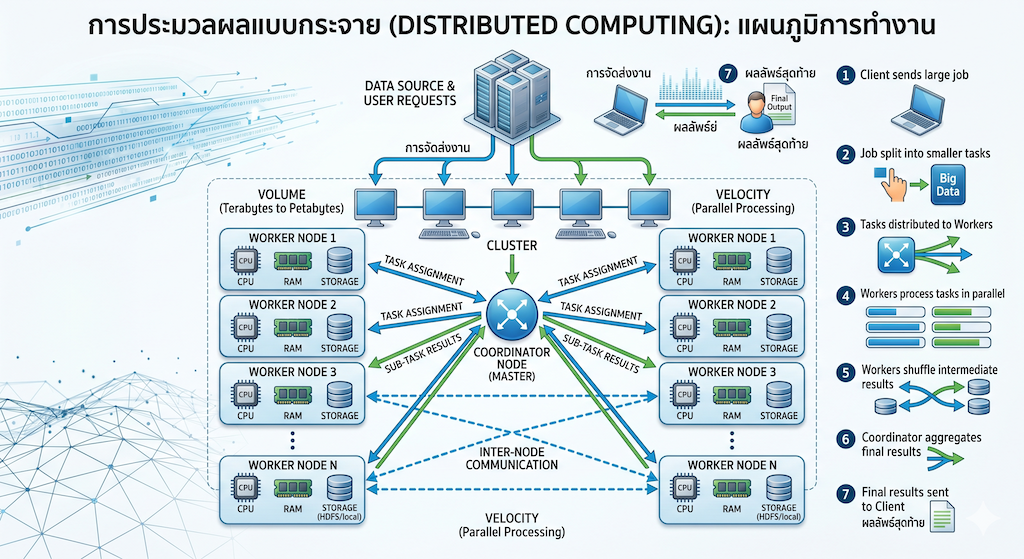
Business Value: ยืดหยุ่นสูงและต้นทุนต่ำ องค์กรสามารถเริ่มต้นจากระบบขนาดเล็ก และค่อย ๆ เพิ่มคอมพิวเตอร์เข้าสู่ระบบได้ตลอดเวลา (Horizontal Scaling) ตามปริมาณข้อมูลที่เติบโตขึ้น โดยไม่ต้องลงทุนซื้อซูเปอร์คอมพิวเตอร์ราคาแพงตั้งแต่เริ่มแรก
3.6.2 Apache Hadoop: ผู้บุกเบิกการจัดเก็บข้อมูลราคาประหยัด
Hadoop คือเทคโนโลยีแรก ๆ ที่ทำให้แนวคิด Distributed Computing กลายเป็นจริงในเชิงพาณิชย์ โดยมีหัวใจสำคัญสองส่วนคือ ระบบจัดเก็บไฟล์แบบกระจาย (HDFS) และระบบประมวลผล (MapReduce)

- แก้โจทย์ข้อไหนใน 4Vs?: Volume (ปริมาณ) และ Variety (ความหลากหลาย)
- Business Application: Hadoop เหมาะสำหรับสิ่งที่เราเรียกว่า “Batch Processing” หรือการประมวลผลข้อมูลชุดใหญ่ที่อยู่นิ่งแล้ว เช่น การคำนวณยอดขายสะสมรายเดือน การเก็บประวัติพฤติกรรมลูกค้าย้อนหลังหลายปีเพื่อทำ Data Lake หรือการวิเคราะห์ข้อมูลดิบ (Unstructured Data) ที่ยังไม่ได้จัดระเบียบ
3.6.3 Apache Spark: ตัวเร่งความเร็วในการวิเคราะห์ข้อมูล
แม้ Hadoop จะจัดเก็บข้อมูลได้ดี แต่การประมวลผลผ่านฮาร์ดดิสก์แบบเดิมนั้นช้าเกินไปสำหรับธุรกิจยุคใหม่ Apache Spark จึงถูกพัฒนาขึ้นมาเพื่อประมวลผลข้อมูลบนหน่วยความจำชั่วคราว (In-Memory Processing) ซึ่งทำงานได้เร็วกว่า Hadoop ถึง 100 เท่า

- แก้โจทย์ข้อไหนใน 4Vs?: Volume (ปริมาณ) และ Velocity (ความเร็ว)
- Business Application: Spark ช่วยให้ทีมนักวิเคราะห์ข้อมูล (Data Scientists) สามารถรันโมเดลพยากรณ์พฤติกรรมลูกค้า หรือทำระบบแนะนำสินค้า (Recommendation Engine) แบบจำเพาะบุคคลได้เสร็จสิ้นภายในไม่กี่นาที แทนที่จะต้องรอข้ามคืนเหมือนในอดีต
3.6.4 ข้อมูลสตรีมมิ่ง (Streaming Data): การวิเคราะห์ในเสี้ยววินาทีเพื่อคว้าโอกาส
โลกธุรกิจปัจจุบันไม่ได้ขับเคลื่อนด้วยข้อมูลรายวันอีกต่อไป ข้อมูลจำนวนมากเกิดขึ้นในลักษณะ Streaming Data หรือ “ข้อมูลที่ไหลเวียนมาอย่างต่อเนื่องไม่ขาดสาย” เช่น ข้อมูลการกดรับชมวิดีโอ สัญญาณเซนเซอร์จากเครื่องจักร หรือยอดธุรกรรมทางการเงิน
- แก้โจทย์ข้อไหนใน 4Vs?: Velocity (ความเร็วที่ต้องการการตอบสนองทันที)
- Business Application: การประมวลผลข้อมูลแบบสตรีมมิ่งทำให้เกิด Real-time Analytics ซึ่งจำเป็นอย่างยิ่งในกลยุทธ์ธุรกิจสมัยใหม่ ตัวอย่างเช่น:
- การตรวจจับการทุจริต (Fraud Detection): ธนาคารต้องวิเคราะห์และระงับบัตรเครดิตที่ถูกขโมยทันทีในเสี้ยววินาทีที่เกิดธุรกรรม ไม่ใช่รอตรวจเจอในรายงานสรุปสิ้นวัน
- การซ่อมบำรุงเชิงคาดการณ์ (Predictive Maintenance): สายการบินวิเคราะห์สัญญาณความร้อนจากเครื่องยนต์เครื่องบินที่ส่งมาตลอดเวลาขณะบิน เพื่อสั่งซ่อมบำรุงทันทีที่เครื่องแลนดิ้ง ก่อนที่อุปกรณ์จะเกิดความเสียหายจริง
3.7 แบบฝึกหัดท้ายบท
การแปลงโจทย์ธุรกิจ (Problem Transformation): จงยกตัวอย่างปัญหาทางธุรกิจที่พบได้ทั่วไปในอุตสาหกรรมดิจิทัลมา 1 ตัวอย่าง และอธิบายขั้นตอนการแปลงให้เป็นปัญหาทางข้อมูล (Data Problem) โดยระบุตัวแปรต้น (Input) และตัวแปรตาม (Output) ที่เกี่ยวข้อง
คุณลักษณะ 4Vs ของ Big Data: จงอธิบายลักษณะสำคัญของ 4Vs (Volume, Velocity, Variety, Veracity) พร้อมยกตัวอย่างบริษัทหรือแอปพลิเคชันในประเทศไทยที่ใช้ประโยชน์จากแต่ละ V อย่างเป็นรูปธรรม
รากฐานทางสถิติ (Statistical Foundations): “กฎจำนวนมาก” (Law of Large Numbers) และ “ทฤษฎี Glivenko-Cantelli” มีความสำคัญอย่างไรต่อความน่าเชื่อถือของการวิเคราะห์ Big Data? หากเรามีข้อมูลขนาดเล็ก (Small Data) จะส่งผลกระทบต่อการตัดสินใจเชิงธุรกิจอย่างไร?
ประเภทของแบบจำลอง: จงเปรียบเทียบความแตกต่างระหว่างการจำแนกประเภท (Classification) และการจัดกลุ่ม (Clustering) ในมิติของวัตถุประสงค์การใช้งานและประเภทของข้อมูลที่ใช้ (Supervised vs. Unsupervised Learning)
การวิเคราะห์ Workflow: จากแผนภาพกระบวนการวิเคราะห์ข้อมูลทางธุรกิจอย่างเป็นระบบที่ได้ศึกษาไป นักศึกษาคิดว่าขั้นตอนใดมีความท้าทายมากที่สุดสำหรับการทำธุรกิจในยุคปัจจุบัน? จงให้เหตุผลประกอบโดยเชื่อมโยงกับประสบการณ์หรือข่าวสารทางธุรกิจที่นักศึกษาเคยพบ
จริยธรรมข้อมูล (Data Ethics): ในขั้นตอนการจัดการข้อมูล (Data Preparation) หากนักศึกษาพบข้อมูลที่ระบุตัวตนลูกค้าได้ชัดเจน นักศึกษาควรมีแนวทางปฏิบัติอย่างไรเพื่อให้สอดคล้องกับจรรยาบรรณวิชาชีพและกฎหมาย PDPA