graph TD
%% Define styles for clarity (Plain text is safer)
classDef process fill:#d1d8e0,stroke:#2d98da,stroke-width:2px,color:black;
classDef decision fill:#ffe0b2,stroke:#e67e22,stroke-width:2px,color:black;
classDef startend fill:#a55eea,stroke:#8854d0,stroke-width:2px,color:white;
%% Workflow Nodes (Use parenthetical for node shape, but keep text simple)
Start([START: เตรียมข้อมูล]) --> Prep[1. กำหนดจำนวนกลุ่ม K]
Prep --> Init[2. สุ่มจุดศูนย์กลางเริ่มต้น]
%% The Core Loop
Init --> Assign
subgraph The_KMeans_Loop [กระบวนการทำซ้ำ]
Assign[3. จัดข้อมูลเข้ากลุ่มที่ใกล้ที่สุด]:::process
Assign --> Update[4. คำนวณจุดศูนย์กลางใหม่]:::process
end
%% Convergence Check
Update --> Decide{"5. ผลลัพธ์ 'นิ่ง' หรือไม่?"}:::decision
%% Loops back if NO
Decide -- "ไม่" --> Assign
%% Ends if YES
Decide -- "ใช่" --> Finish([FINISH: ได้กลุ่มข้อมูลสมบูรณ์])
%% Assign classes for styling
class Start,Finish startend;
class Prep,Init,Assign,Update process;
class Decide decision;
12 การเรียนรู้แบบไม่มีผู้สอนสำหรับวิทยาการข้อมูล

จาก Figure 12.1 นศ. จะแบ่งกลุ่มในภาพอย่างไรดี?
ในบทที่แล้ว นักศึกษาของเราได้สวมบทบาทเป็น “ผู้คุมพยานหลักฐาน” ที่คอยเฉลยคำตอบให้เครื่องจักรเรียนรู้ว่าแบบไหนคือ “ผ่าน” หรือ “ไม่ผ่าน” นั่นคือโลกของการเรียนรู้แบบมีผู้สอนที่เน้นการพยากรณ์อนาคตจากอดีต
แต่ในโลกจริงของวิทยาศาสตร์ข้อมูล ในหลายครั้งที่เราเดินเข้าไปในคลังพยานหลักฐานขนาดมหาศาล… แล้วเรา “ไม่มีคำตอบ”
เราอาจจะมีข้อมูลพฤติกรรมการซื้อของลูกค้าหลายแสนคน แต่เราไม่รู้ว่าใครเป็นพวกเดียวกับใคร?
เราอาจจะมีข้อมูลรายการสินค้าที่ลูกค้าซื้อร่วมกัน แต่เราไม่รู้ว่ามันมี “กฎที่ซ่อนอยู่” (Hidden Rules) ว่าถ้าซื้อชิ้นนี้แล้วจะซื้อชิ้นนั้นหรือไม่?
การเรียนรู้แบบไม่มีผู้สอน (Unsupervised Learning) คือ อัลกอริทึมที่เรียนรู้จากข้อมูลที่ “ไม่มีป้ายกำกับ” (Unlabeled Data) หมายความว่าในชุดข้อมูลจะไม่มีตัวแปรเป้าหมาย (\(Y\)) หรือคำตอบเฉลยมาให้ เครื่องจักรมีหน้าที่เพียงอย่างเดียวคือ “การหาความสัมพันธ์หรือรูปแบบที่ซ่อนอยู่” (Hidden Patterns) ภายในข้อมูลเหล่านั้นเอง
ปรัชญาการทำงาน: “The Self-Organization” หากการเรียนรู้แบบมีผู้สอนคือนักเรียนที่ทำข้อสอบโดยมีคุณครูคอยตรวจคำเฉลยให้การเรียนรู้แบบไม่มีผู้สอนก็เปรียบเสมือน “นักสืบ” ที่ได้รับมอบหมายให้เข้าไปในคลังพยานหลักฐานที่ยุ่งเหยิง แล้วต้องจัดระเบียบข้อมูลเหล่านั้นออกมาเป็นกลุ่มๆ ตามความคล้ายคลึงกัน (Similarity) [1] จาก Table 12.1 แสดงความแตกต่างระหว่าการเรียนรู้แบบมีผู้กับการเรียนรู้แบบไม่มีผู้สอน
| ลักษณะการเปรียบเทียบ | การเรียนรู้แบบมีผู้สอน | การเรียนรู้แบบไม่มีผู้สอน |
|---|---|---|
| ข้อมูลนำเข้า (Data) | มีทั้งตัวแปรอิสระ (\(X\)) และคำตอบ (\(Y\)) | มีเพียงตัวแปรอิสระ (\(X\)) เท่านั้น |
| เป้าหมาย (Goal) | พยากรณ์ (Predict) ผลลัพธ์ในอนาคต | หาโครงสร้างหรือกลุ่ม (Pattern) ของข้อมูล |
| การประเมินผล | วัดจากความแม่นยำ (Accuracy, MSE) | วัดจากความหมาย (Interpretability/Metrics) |
| ตัวอย่างงาน | พยากรณ์ราคาบ้าน, แยกอีเมลขยะ | แบ่งกลุ่มลูกค้า, แนะนำสินค้าที่ซื้อร่วมกัน |
ในบทนี้ เราจะเรียนรู้เทคนิคหลักที่ใช้กันอย่างแพร่หลายในวงการวิทยาการข้อมูล
การแบ่งกลุ่ม(Clustering) คือการจัดกลุ่มข้อมูลที่มีลักษณะ “ใกล้เคียงกัน” ให้อยู่ในกลุ่มเดียวกัน และข้อมูลที่ “ต่างกัน” ให้อยู่คนละกลุ่ม
คณิตศาสตร์เบื้องหลัง: ใช้การวัด “ระยะห่าง” (Distance Metrics) เช่น ระยะห่างแบบยุคลิด (Euclidean Distance) เป็นตัวตัดสินความคล้ายคลึง [2]
ตัวอย่าง: การแบ่งกลุ่มนักศึกษาตามพฤติกรรมการเข้าห้องสมุดและการใช้จ่าย เพื่อออกแบบกิจกรรมที่เหมาะสม
การหาความสัมพันธ์ (Association Rules) คือการหา “กฎ” ที่บอกว่าถ้าเหตุการณ์ A เกิดขึ้น มีโอกาสเท่าไหร่ที่เหตุการณ์ B จะเกิดขึ้นตามมา
แนวคิดหลัก: มักใช้ในงานการวิเคราะห์ตะกร้าตลาด (Market Basket Analysis)
ตัวอย่าง: ข้อมูลในห้างสรรพสินค้าพบว่า “คนที่ซื้อผ้าอ้อม มักจะซื้อเบียร์ไปด้วยในเวลาเดียวกัน” (กฎที่ซ่อนอยู่)
12.1 การเรียนรู้ของเครื่องรู้ได้อย่างไรว่าข้อมูลสองชิ้นมีความคล้ายกัน?
ในโลกของข้อมูล ความคล้ายไม่ได้ดูด้วยตาเปล่า แต่ดูด้วย “ระยะห่าง” (Distance) และ “น้ำหนัก” (Weight)
12.1.1 พื้นฐานการวัดความคล้ายคลึง (Similarity and Distance Measures)
ในการเรียนรู้แบบไม่มีผู้สอนคำว่า “ความเหมือน” (Similarity) จะถูกตีความเป็น “ระยะห่าง” (Distance) ยิ่งข้อมูลมีระยะห่างกันน้อย (สั้น) แสดงว่ามีความเหมือนกันมาก และหากระยะห่างกันมาก แสดงว่ามีความต่างกันมาก (Dissimilarity)
- การวัดระยะห่างสำหรับข้อมูลตัวเลข (Numerical Distance)
มาตรวัดที่ได้รับความนิยมสูงสุดและนักศึกษาควรคำนวณมือเป็นคือ
12.2 การวัดความคล้ายสำหรับข้อมูลหมวดหมู่ (Categorical Similarity)
ในงานของกฏความสัมพันธ์ หรือข้อมูลที่มีแต่ “ใช่/ไม่ใช่” (Binary) เราจะไม่ได้วัดระยะห่างเป็นเซนติเมตร แต่เราจะวัดจาก “การเกิดขึ้นร่วมกัน” (Overlap)
12.3 การเตรียมข้อมูล: การปรับมาตรฐานข้อมูล (Standardization & Normalization)
อัลกอริทึมการจัดกลุ่มข้อมูลส่วนใหญ่ เช่น K-Means และ Hierarchical Clustering ใช้ “ระยะห่างทางคณิตศาสตร์” (Distance Measures) ในการพิจารณาว่าข้อมูลใดมีความใกล้เคียงกันและควรอยู่ในกลุ่มเดียวกัน
ปัญหา: ตัวแปรแต่ละตัวมักมีหน่วยวัด (Units) และช่วงของค่า (Scales) ที่แตกต่างกันมาก เช่น
\(X_1\): Income (รายได้) - มีค่าเป็นหลัก หมื่น/แสน (10,000 - 100,000)
\(X_2\): Age (อายุ) - มีค่าเป็นหลัก สิบ (20 - 60)
หากไม่ปรับสเกลข้อมูล: เครื่องจะมองว่าความต่างของรายได้ 1,000 บาท มีความสำคัญมากกว่าความต่างของอายุ 10 ปี เพียงเพราะตัวเลขรายได้มัน “ตัวใหญ่กว่า” มันจะทำให้ “รายได้” กลายเป็นพยานหลักฐานเพียงคนเดียวที่กำหนดผลการจัดกลุ่มทั้งหมด และเพิกเฉยต่อตัวแปรอื่นๆ ไปโดยปริยาย
12.3.1 เทคนิคการปรับสเกลข้อมูล (Scaling Techniques)
เราจะมาเรียนรู้ 2 วิธีมาตรฐานที่ใช้กันบ่อย
12.4 K-Means Clustering: การจัดกลุ่มด้วยจุดศูนย์กลาง
K-Means Clustering เป็นหนึ่งในอัลกอริทึมสำหรับการจัดกลุ่มข้อมูล (Clustering) ที่ได้รับความนิยมมากที่สุดในกลุ่มการเรียนรู้แบบไม่มีผู้สอน (Unsupervised Learning) เนื่องจากมีแนวคิดที่เรียบง่าย เข้าใจง่าย และสามารถประยุกต์ใช้กับข้อมูลได้หลากหลายประเภท [5]
12.4.1 ขั้นตอนการทำงานของ K-Means
K-Means เป็นอัลกอริทึมแบบ Iterative (ทำซ้ำ) จนกว่าจะสรุปผลที่ดีที่สุด โดยมีขั้นตอนพื้นฐาน 5 ขั้นตอน ดังนี้ ตาม Figure 12.2
ขั้นตอนที่ 1: กำหนดจำนวนกลุ่ม (Choose K) เราต้องตัดสินใจล่วงหน้าว่าต้องการแบ่งข้อมูลทั้งหมดออกเป็นกี่กลุ่ม (กำหนดค่า \(K\))
- เช่น: ในงาน Workshop นี้ เราอยากแบ่งกลุ่มลูกค้าตามพฤติกรรมการใช้จ่าย เราจึงกำหนด \(K = 3\) (กลุ่มใช้จ่ายต่ำ, กลาง, สูง)
ขั้นตอนที่ 2: สุ่มจุดศูนย์กลางเริ่มต้น (Initialize Centroids) เครื่องจะทำการสุ่มเลือกจุดข้อมูลจำนวน \(K\) จุดขึ้นมาเพื่อทำหน้าที่เป็น “จุดศูนย์กลางชั่วคราว” (Initial Centroids)
- หมายเหตุ: การสุ่มเริ่มต้นที่แตกต่างกัน อาจทำให้ผลลัพธ์สุดท้ายแตกต่างกันเล็กน้อย
ขั้นตอนที่ 3: จัดข้อมูลเข้ากลุ่มที่ใกล้ที่สุด (Assign Points to Closest Centroid) ข้อมูลทุกๆ จุดในชุดข้อมูลจะถูกนำมาคำนวณ “ระยะห่าง” (มักใช้ Euclidean Distance) เทียบกับจุดศูนย์กลางทั้ง \(K\) จุด และจุดข้อมูลนั้นจะถูก “จัดเข้ากลุ่ม” ของศูนย์กลางที่มันอยู่ใกล้ที่สุด
ขั้นตอนที่ 4: คำนวณจุดศูนย์กลางใหม่ (Update Centroids) เมื่อทุกจุดมีกลุ่มแล้ว เครื่องจะคำนวณหา “ค่าเฉลี่ยทางคณิตศาสตร์” ใหม่ของจุดข้อมูลทั้งหมดที่อยู่ในแต่ละกลุ่ม จุดค่าเฉลี่ยใหม่นี้จะกลายเป็น “จุดศูนย์กลางที่แท้จริง” ของกลุ่มนั้นในการทำซ้ำรอบถัดไป
ขั้นตอนที่ 5: ทำซ้ำจนกว่าจะนิ่ง (Repeat until Convergence) เครื่องจะกลับไปทำ ขั้นตอนที่ 3 และ 4 ซ้ำไปเรื่อยๆ จนกว่าจะเกิดสภาวะใดสภาวะหนึ่ง:
จุดศูนย์กลาง (Centroids) ไม่มีโมเมนตัมในการเคลื่อนที่แล้ว (อยู่ที่เดิม)
ไม่มีจุดข้อมูลจุดใดเปลี่ยนกลุ่มอีกแล้ว
ครบจำนวนรอบ (Iterations) ที่กำหนดไว้ล่วงหน้า
12.5 การหาจำนวนกลุ่ม (K) ที่เหมาะสมที่สุด (Optimal Cluster Number)
ปัญหาโลกแตกของ K-Means: เลือก K เท่าไหร่ดี?
เราไม่สามารถเดาสุ่มค่า \(K\) ได้ เพราะถ้าค่า \(K\) น้อยเกินไป ข้อมูลที่ต่างกันมากอาจจะถูกมัดรวมกัน แต่ถ้าค่า \(K\) มากเกินไป ข้อมูลก็จะถูกแบ่งย่อยจนไม่เห็นภาพรวมธุรกิจ (ในที่สุดข้อมูลทุกจุดจะกลายเป็นจุดศูนย์กลางของตัวเอง)
เราจึงต้องมีไม้บรรทัดทางคณิตศาสตร์ 2 ชิ้นมาช่วยตัดสิน
ในทางปฏิบัติ เรามักจะใช้ Elbow Method เพื่อบีบวงของค่า \(K\) ที่น่าจะเป็นไปได้ (เช่น น่าจะอยู่ระหว่าง \(K=2\) ถึง \(K=4\)) จากนั้นเราจะใช้ Silhouette Score มาเป็นตัวตัดสินคนสุดท้ายว่า \(K\) ไหนคือค่าที่สมดุลที่สุด… แต่อย่าลืมนะว่าคณิตศาสตร์บอกได้แค่ ‘จุดที่สวยที่สุด’ หน้าที่ของคุณคือการดูว่ากลุ่มที่ได้มานั้น ‘ตอบโจทย์ธุรกิจ’ (Interpretation) หรือไม่ด้วย [6]
12.6 ปฏิบัติการ: กระบวนการ K-Means ด้วย iris dataset
ในหัวข้อนี้ เราจะสวมบทบาทเป็น “นักชีววิทยา” เดินเข้าไปในสวนดอกไม้ Iris เพื่อจัดกลุ่มดอกไม้ 150 ดอก โดยดูจากขนาดใบเลี้ยง (Sepal) และกลีบดอก (Petal) โดยที่เราไม่รู้มาก่อนว่ามันมีกี่สายพันธุ์
ขั้นตอนที่ 1: เตรียมพยานหลักฐาน (Data Preparation)
ก่อนอื่นเราต้องโหลดข้อมูลและ “ทำความสะอาด” โดยการเอาเฉลย (Species) ออกไปก่อน เพราะในโลกจริงของ Unsupervised เราไม่มีเฉลย
นักศึกษาสามารถ download ได้จาก
GOOGLEDRIVE: ch12/iris_unlabeled.csv
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width |
|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 |
| 4.9 | 3.0 | 1.4 | 0.2 |
| 4.7 | 3.2 | 1.3 | 0.2 |
| 4.6 | 3.1 | 1.5 | 0.2 |
| 5.0 | 3.6 | 1.4 | 0.2 |
| 5.4 | 3.9 | 1.7 | 0.4 |
ขั้นตอนที่ 2: ปรับข้อมูลด้วยวิธีการทำให้เป็นมาตรฐาน (Standardization)
เนื่องจากขนาดของ Sepal และ Petal มีช่วงตัวเลขที่แตกต่างกัน เราต้องปรับให้ทุกตัวแปรมี “สิทธิ์มีเสียงเท่ากัน” ด้วย Z-score
ตัวอย่างข้อมูลที่ทำแปลงแล้ว
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width |
|---|---|---|---|
| -0.8976739 | 1.0156020 | -1.335752 | -1.311052 |
| -1.1392005 | -0.1315388 | -1.335752 | -1.311052 |
| -1.3807271 | 0.3273175 | -1.392399 | -1.311052 |
| -1.5014904 | 0.0978893 | -1.279104 | -1.311052 |
| -1.0184372 | 1.2450302 | -1.335752 | -1.311052 |
| -0.5353840 | 1.9333146 | -1.165809 | -1.048667 |
ขั้นตอนที่ 3: หาจำนวนกลุ่ม (K) ที่เหมาะสม (Optimal K)
เราจะใช้ Elbow Method ร่วมกับ Silhouette Score เพื่อตัดสินใจเลือกค่า \(K\) ทางวิทยาศาสตร์
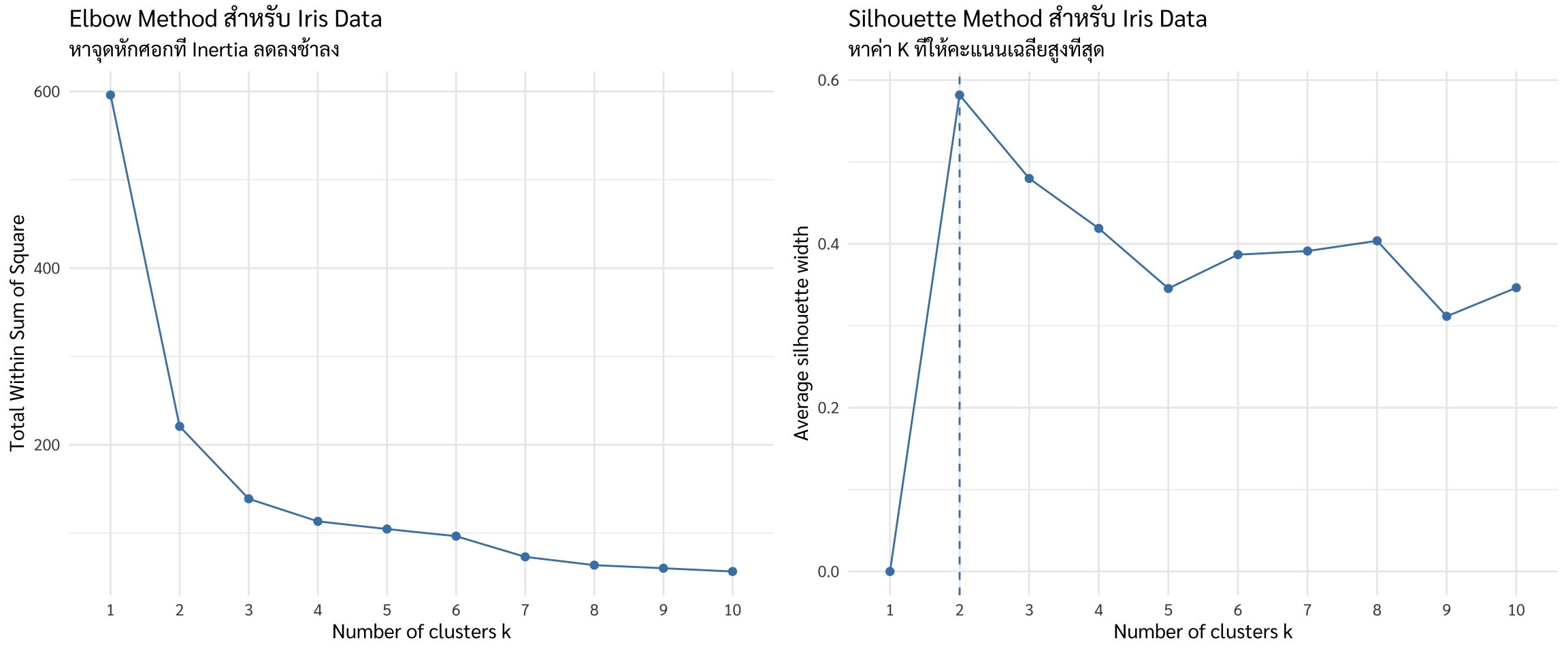
การวิเคราะห์ของนักชีววิทยาที่เชี่ยวชาญการวิทยาการข้อมูล
Elbow: กราฟหักศอกชัดเจนที่ \(K=2\) และ \(K=3\)
Silhouette: คะแนนเฉลี่ยสูงที่สุดอยู่ที่ \(K=2\) แต่ค่า \(K=3\) ก็ยังให้คะแนนที่สูงและเป็นทางเลือกที่น่าสนใจในทางชีววิทยา
ตัดสินใจ: เพื่อให้เห็นการแบ่งกลุ่มที่ชัดเจนและตอบโจทย์ว่าดอกไม้มีหลายสายพันธุ์ เราจะเลือก \(K=3\)
ขั้นตอนที่ 4: รันแบบจำลอง K-Means (Model Training)
เราจะรัน K-Means ด้วยค่า \(K=3\) ที่เราเลือก
K-means clustering with 3 clusters of sizes 50, 53, 47
Cluster means:
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 -1.01119138 0.85041372 -1.3006301 -1.2507035
2 -0.05005221 -0.88042696 0.3465767 0.2805873
3 1.13217737 0.08812645 0.9928284 1.0141287
Clustering vector:
[1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
[38] 1 1 1 1 1 1 1 1 1 1 1 1 1 3 3 3 2 2 2 3 2 2 2 2 2 2 2 2 3 2 2 2 2 3 2 2 2
[75] 2 3 3 3 2 2 2 2 2 2 2 3 3 2 2 2 2 2 2 2 2 2 2 2 2 2 3 2 3 3 3 3 2 3 3 3 3
[112] 3 3 2 2 3 3 3 3 2 3 2 3 2 3 3 2 3 3 3 3 3 3 2 2 3 3 3 2 3 3 3 2 3 3 3 2 3
[149] 3 2
Within cluster sum of squares by cluster:
[1] 47.35062 44.08754 47.45019
(between_SS / total_SS = 76.7 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss"
[6] "betweenss" "size" "iter" "ifault" ขั้นตอนที่ 5: วิเคราะห์และตรวจสอบผลลัพธ์ (Visualization & Evaluation)
เราจะวาดกราฟเพื่อดูว่าเครื่องจักรจัดกลุ่มให้เราอย่างไร และท้ายที่สุดเราจะแอบเอาเฉลยจริง (Species) มาเทียบเพื่อดูความแม่นยำ
วาดกราฟ Cluster
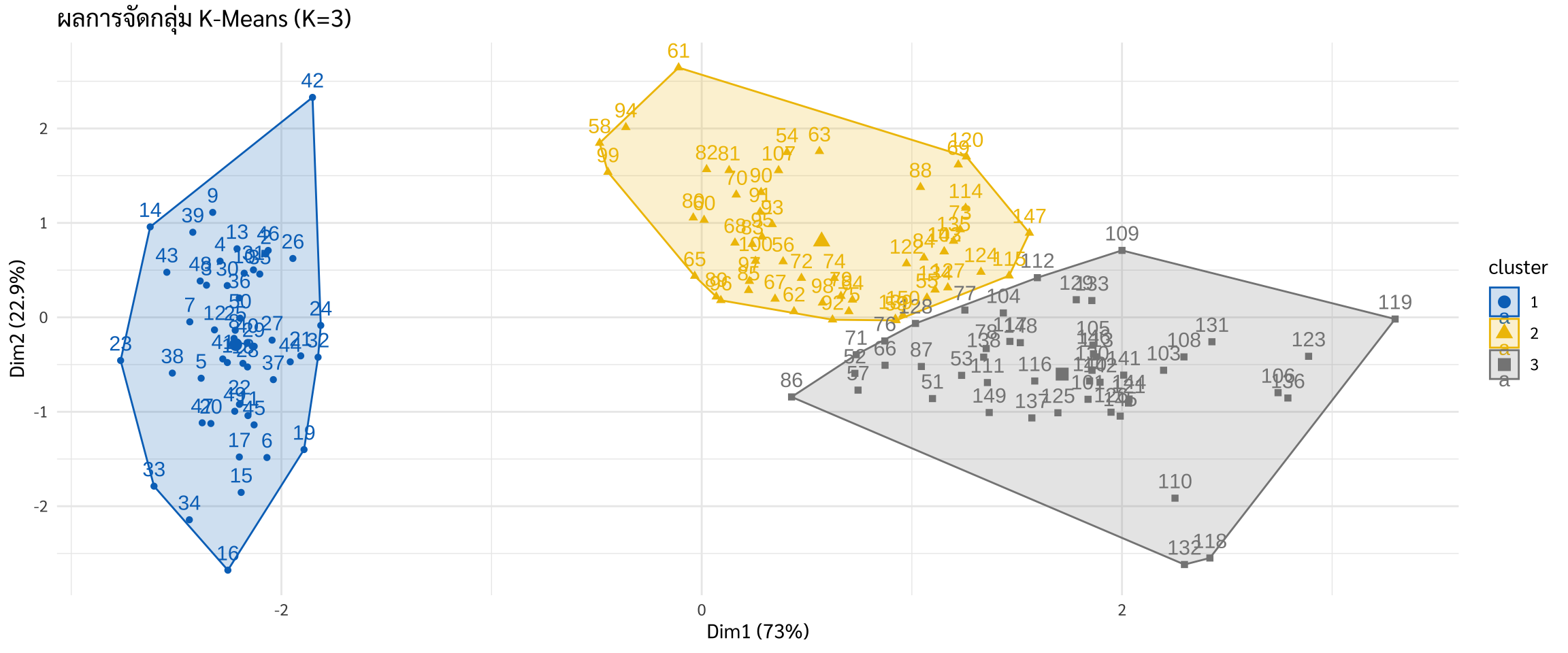
ตรวจสอบกับเฉลยจริง (Validation with Ground Truth)
ในเคสนี้เรามีเฉลย เราจึงแอบดูได้ว่าเครื่องจัดกลุ่มดอกไม้ได้ตรงตามสายพันธุ์จริงหรือไม่?
| setosa | versicolor | virginica |
|---|---|---|
| 50 | 0 | 0 |
| 0 | 39 | 14 |
| 0 | 11 | 36 |
ในโลกจริงที่คุณไม่มีเฉลย หน้าที่ของคุณคือการรันกระบวนการทั้งหมดนี้ให้ครบถ้วน แล้วใช้ความรู้ในบริบทธุรกิจมาตั้งชื่อกลุ่มข้อมูลเหล่านั้นด้วยตัวเอง
12.7 Hierarchical Clustering: การจัดกลุ่มแบบลำดับชั้น
หาก K-Means คือการ “สุ่มหาหัวหน้าโต๊ะ” Hierarchical Clustering ก็คือการ “จับคู่พยานหลักฐานที่เหมือนกันที่สุด” เข้าด้วยกันไปเรื่อยๆ จนกลายเป็นครอบครัวใหญ่
- แนวคิดแบบ Agglomerative (Bottom-Up) วิธีที่นิยมที่สุดคือการมองจาก “ล่างขึ้นบน” โดยมีขั้นตอนดังนี้ ตาม Figure 12.5
graph TD
%% Style Definitions
classDef startend fill:#a55eea,stroke:#8854d0,stroke-width:2px,color:white;
classDef process fill:#d1d8e0,stroke:#2d98da,stroke-width:2px,color:black;
classDef decision fill:#ffe0b2,stroke:#e67e22,stroke-width:2px,color:black;
%% Workflow
Start([START: ข้อมูล N จุด]) --> Init[1. ให้ข้อมูลแต่ละจุดเป็น 1 กลุ่มอิสระ<br/>Cluster = N กลุ่ม]:::process
Init --> Calc[2. คำนวณระยะห่างระหว่างกลุ่มทั้งหมด<br/>ด้วย Distance Matrix]:::process
%% Loop
Calc --> Merge[3. รวม 2 กลุ่มที่ใกล้กันที่สุด<br/>เข้าเป็นกลุ่มเดียวกัน]:::process
Merge --> Check{"4. รวมครบจนเหลือ<br/>กลุ่มเดียวหรือยัง?"}:::decision
%% Loop back
Check -- "ยัง (N > 1)" --> Calc
%% Finish
Check -- "ใช่ (N = 1)" --> Finish([FINISH: ได้โครงสร้างต้นไม้ Dendrogram])
class Start,Finish startend;
1.1 เริ่มต้นด้วยการมองว่าข้อมูลทุกจุดคือ 1 กลุ่มอิสระ (ถ้ามีข้อมูล 100 จุด ก็มี 100 กลุ่ม)
1.2 หาข้อมูล 2 จุดที่ “ใกล้กันที่สุด” (มีระยะห่างน้อยที่สุด) แล้วยุบรวมกันเป็นกลุ่มเดียว
1.3 ทำซ้ำขั้นตอนที่ 2 ไปเรื่อยๆ โดยการรวมกลุ่มที่ใกล้กันเข้าด้วยกัน
1.4 หยุดกระบวนการเมื่อข้อมูลทั้งหมดถูกรวมเข้าเป็น กลุ่มใหญ่กลุ่มเดียว
- เดนโดรแกรม (Dendrogram): แผนผังต้นไม้บอกสายสัมพันธ์ จุดเด่นที่สุดของ Hierarchical Clustering คือการแสดงผลผ่านเดนโดรแกรม (Dendrogram) ซึ่งเปรียบเสมือนแผนผังตระกูล (Family Tree) ของข้อมูลตาม Figure 12.6
graph BT
%% Tree Structure (Bottom-Up Logic)
A[Data A] --- AB(( ))
B[Data B] --- AB
C[Data C] --- ABC(( ))
AB --- ABC
D[Data D] --- DE(( ))
E[Data E] --- DE
ABC --- Root((ALL DATA))
DE --- Root
%% Visual Indicators for Cutting
subgraph Cut_High [ตัดที่ระดับความสูงมาก]
Root
end
subgraph Cut_Low [ตัดที่ระดับความสูงน้อย]
ABC
DE
end
%% Annotations
note1{{หากตัดระดับนี้: จะได้ 2 กลุ่มใหญ่}}
note2{{หากตัดระดับนี้: จะได้ 3 กลุ่มย่อย}}
%% Link notes to subgraphs (conceptual)
class ABC,DE process;
class Root decision;
- แกนตั้ง (Height/Distance): บอกว่าข้อมูลกลุ่มนั้นๆ ถูกรวมกันที่ระยะห่างเท่าไหร่ ยิ่งรวมกันที่ระดับสูง แสดงว่าข้อมูลสองกลุ่มนั้นมีความ “ต่าง” กันมาก
- แกนนอน: แสดงข้อมูลรายจุด
💡 จุดตัดสินใจของนักวิทยาศาสตร์ข้อมูล: ใน K-Means เราต้องกำหนด \(K\) ล่วงหน้า แต่ใน Hierarchical Clustering เราสามารถ “มาเลือกตัดกิ่ง (Cut the Tree)” ในภายหลังได้ ถ้าเราตัดที่ระดับความสูงที่น้อย เราจะได้กลุ่มย่อยจำนวนมาก แต่ถ้าเราตัดที่ระดับความสูงมาก เราจะได้กลุ่มใหญ่จำนวนน้อย
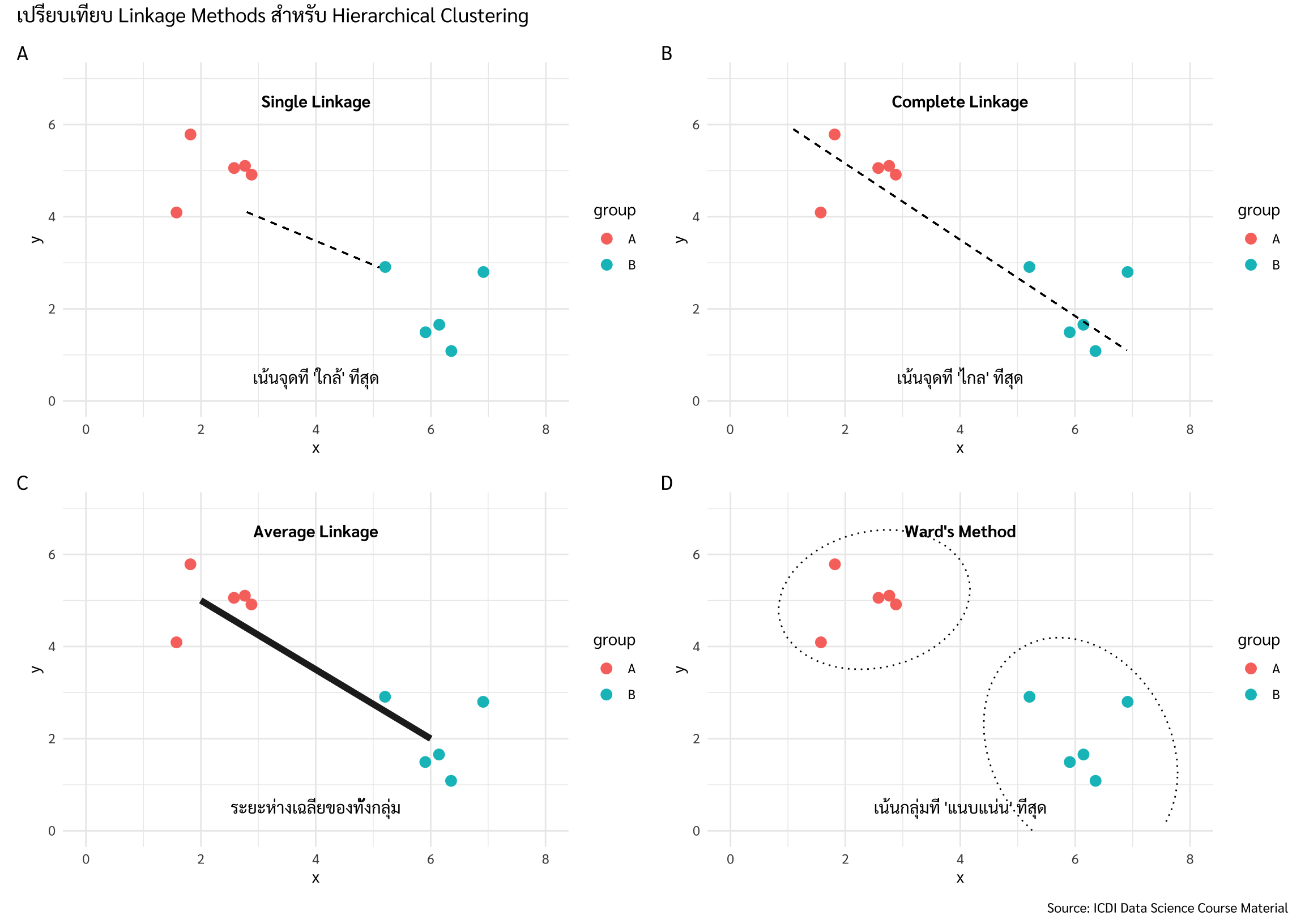
การวัดระยะห่างระหว่างกลุ่ม (Linkage Methods) เมื่อข้อมูลถูกรวมเป็นกลุ่มแล้ว การจะไปรวมกับกลุ่มอื่นต่อ เครื่องต้องตัดสินใจว่าจะใช้ระยะตรงไหนเป็นเกณฑ์? (นี่คือจุดที่นักศึกษาต้องเลือกใน Orange):
Single Linkage (A): ใช้ระยะห่างระหว่างจุดที่ “ใกล้ที่สุด” ของสองกลุ่ม (มักได้กลุ่มที่รูปร่างยาวคล้ายโซ่)
Complete Linkage (B): ใช้ระยะห่างระหว่างจุดที่ “ไกลที่สุด” ของสองกลุ่ม (มักได้กลุ่มที่แน่นและเป็นวงกลม)
Average Linkage (C): ใช้ระยะห่าง “เฉลี่ย” ของทุกจุดระหว่างกลุ่ม (ให้ความสมดุล)
Ward’s Method (D): (นิยมที่สุด) มุ่งเน้นการรวมกลุ่มที่ทำให้ ค่าความแปรปรวน (Variance) ภายในกลุ่มเพิ่มขึ้นน้อยที่สุด ผลลัพธ์มักจะได้กลุ่มที่มีขนาดใกล้เคียงกันและแนบแน่น
12.7.1 หลักการตัดสินใจเลือกจำนวนกลุ่ม (Selecting K)
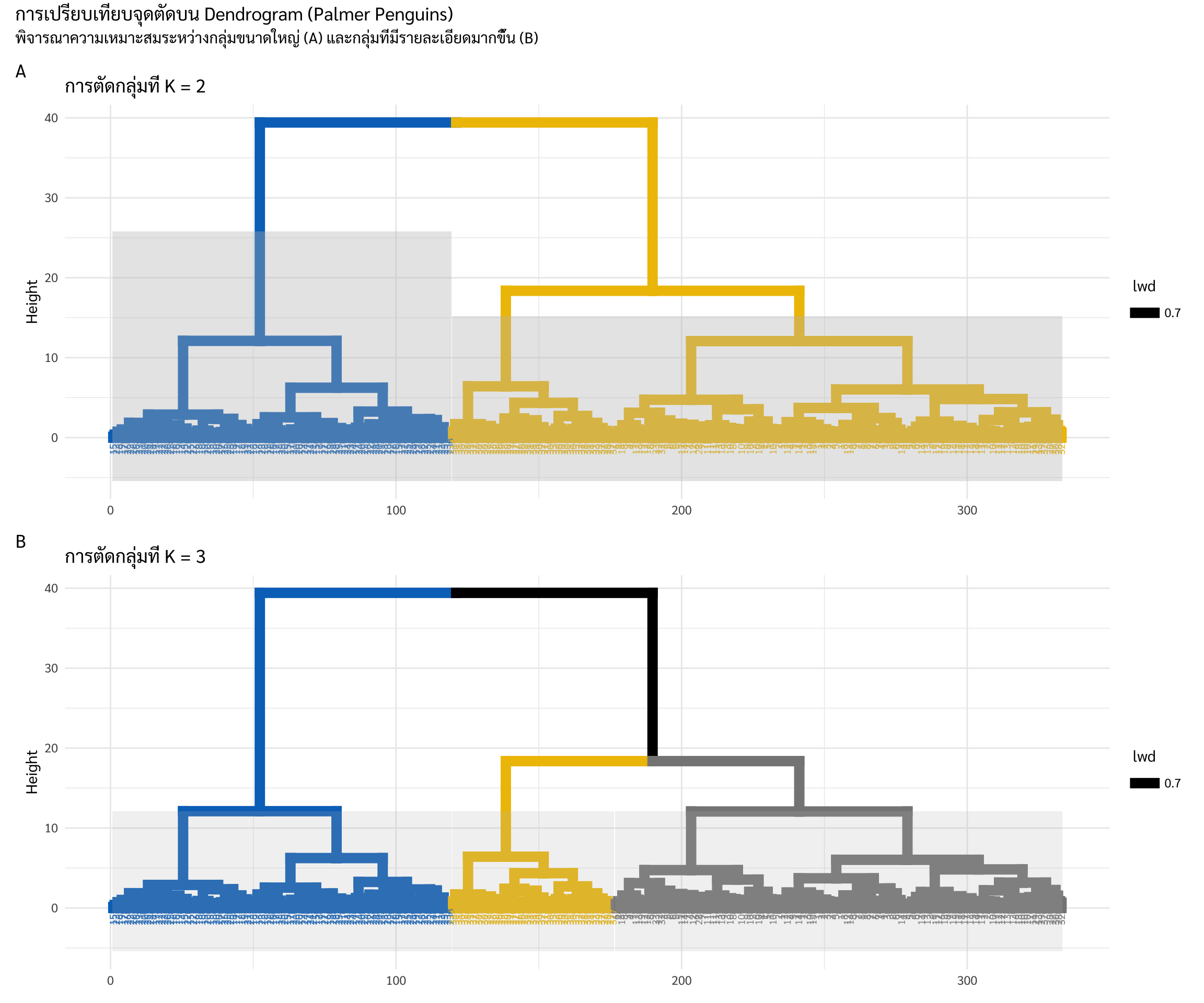
ใน Hierarchical Clustering เราไม่ได้กำหนด \(K\) ตั้งแต่ต้น แต่เราจะใช้ “การตัดกิ่ง” (Cutting the Dendrogram) โดยมีหลักการพิจารณาดังนี้
วิธีพิจารณาจากแนวราบ (The Longest Vertical Distance) เป็นวิธีที่นิยมที่สุดและดูง่ายที่สุดด้วยตาเปล่าบนเดนโดรแกรม
หลักการ: ให้มองหาช่วงของ “เส้นเชื่อมแนวตั้ง” ที่มีความยาวมากที่สุดโดยไม่มีเส้นแนวราบมาตัดผ่าน
การตัดสินใจ: เราจะลากเส้นตัดแนวราบผ่านช่วงที่ “ว่าง” และ “ยาว” ที่สุดนั้น
ความหมาย: ช่วงที่เส้นแนวตั้งยาวๆ หมายความว่าข้อมูลกลุ่มเหล่านั้นมีความแตกต่างของระยะห่างกันมาก การตัดที่จุดนี้จึงทำให้เราได้กลุ่มที่แยกออกจากกันอย่างชัดเจนที่สุด
วิธีทางสถิติ (Statistical Metrics) หากการมองด้วยตาเปล่าทำได้ยาก เราสามารถใช้มาตรวัดเดียวกับ K-Means มาช่วยยืนยันได้
Silhouette Score: รันการตัดกิ่งที่ \(K\) ต่างๆ (เช่น \(K=2, 3, 4, ...\)) แล้วเลือก \(K\) ที่ให้คะแนนเฉลี่ยสูงสุด
Elbow Method: ใน Hierarchical Clustering เราจะพิจารณาจากค่า Total Within-Cluster Sum of Squares หลังการตัดกิ่งในแต่ละระดับความสูง
วิธีตามบริบทธุรกิจ (Business/Domain Logic) บางครั้งคณิตศาสตร์อาจจะบอกว่า 2 กลุ่มดีที่สุด แต่ในทางปฏิบัติอาจไม่ตอบโจทย์
- ตัวอย่าง: หากต้องการจัดกลุ่มลูกค้าเพื่อทำโปรโมชั่น ธุรกิจอาจมีงบประมาณรองรับแผนการตลาดได้แค่ 3 รูปแบบ (3 Segments) ดังนั้นการเลือกตัดกิ่งที่ \(K=3\) จึงสมเหตุสมผลกว่าในเชิงการบริหารจัดการ แม้ว่าสถิติจะบอกว่า \(K=2\) สวยกว่าก็ตาม
การตัดเดนโดรแกรม ก็เหมือนกับการตัดสินใจแยกแยะพยานหลักฐาน ถ้าคุณตัดสูงเกินไป คุณจะได้ภาพกว้างที่อาจจะละเลยรายละเอียดสำคัญ แต่ถ้าคุณตัดต่ำเกินไป คุณจะจมอยู่กับกลุ่มย่อยๆ จนหาข้อสรุปไม่ได้ จุดที่เหมาะสมที่สุดมักจะอยู่ตรงช่วง ‘กิ่งที่ยาวที่สุด’ ก่อนที่มันจะเริ่มแตกแขนงย่อยๆ ออกมา
12.8 กรณีศึกษา: การสืบค้นสายพันธุ์นกเพนกวินด้วย Hierarchical Clustering
ในปฏิบัติการนี้ เราจะสวมบทบาทเป็นนักสัตววิทยาที่เดินทางไปสำรวจหมู่เกาะในแอนตาร์กติกา เราพบพยานหลักฐานเป็นนกเพนกวินจำนวนมาก แต่เราแสร้งทำเป็นว่าเราไม่รู้จักสายพันธุ์ของมัน เราจะใช้ความยาวจะงอยปาก (Bill), ความลึกของจะงอยปาก และความยาวปีก (Flipper) มาจัดกลุ่มพวกมัน
ขั้นตอนที่ 1: การเตรียมข้อมูล (Data Cleaning & Preparation) และการปรับมาตรฐานข้อมูล (Standardization)
สามารถดาวน์โหลดชุดข้อมูลได้จากGOOGLEDRIVE: ch12/penguins_clean
ตัวอย่างข้อที่ทำการทำให้เป็นมาตรฐาน (standardization) มาแล้ว
| bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g |
|---|---|---|---|
| -0.8946955 | 0.7795590 | -1.4246077 | -0.5676206 |
| -0.8215515 | 0.1194043 | -1.0678666 | -0.5055254 |
| -0.6752636 | 0.4240910 | -0.4257325 | -1.1885721 |
| -1.3335592 | 1.0842457 | -0.5684290 | -0.9401915 |
| -0.8581235 | 1.7444004 | -0.7824736 | -0.6918109 |
| -0.9312674 | 0.3225288 | -1.4246077 | -0.7228585 |
ขั้นตอนที่ 2: การสร้างสายสัมพันธ์ (Hierarchical Clustering)
เราจะใช้ Ward’s Method และระยะห่างยุคลิด (Euclidean distance) เพราะเราต้องการกลุ่มที่แน่นและมีขนาดที่สมเหตุสมผลสำหรับสายพันธุ์สัตว์
ขั้นตอนที่ 4: ตรวจสอบพยานหลักฐานกับความเป็นจริง (Validation)
นักชีววิทยาจะลองเอาเฉลยจริง (Species) มาวางทับผลการจัดกลุ่มที่ \(K=3\) เพื่อดูว่าคณิตศาสตร์แม่นยำแค่ไหน
| Adelie | Chinstrap | Gentoo |
|---|---|---|
| 146 | 11 | 0 |
| 0 | 0 | 119 |
| 0 | 57 | 0 |
เมื่อเราเข้าใจการ “แบ่งกลุ่ม” ข้อมูลด้วย Clustering ไปแล้ว เครื่องมือชิ้นสุดท้ายในชุดการเรียนรู้แบบไม่มีผู้สอนที่จะขาดไม่ได้เลยสำหรับงานด้านวิทยาศาสตร์ข้อมูลธุรกิจ (Business Data Science) คือการหา “กฎแห่งความสัมพันธ์”
หาก Clustering คือการหาว่า “ใครเป็นพวกเดียวกับใคร” ดังนั้น กฏความสัมพันธ์ (Association Rules) ก็คือการหาว่า “พฤติกรรม A มักจะจูงมือพฤติกรรม B มาด้วยเสมอหรือไม่” นั่นเอง
12.9 Association Rules: กฎแห่งความสัมพันธ์
ในโลกของธุรกิจ ข้อมูลพยานหลักฐานที่สำคัญที่สุดอย่างหนึ่งคือ ข้อมูลการซื้อขาย (Transaction Data) การรู้ว่าลูกค้าซื้ออะไรพร้อมกัน ไม่ได้ช่วยแค่การจัดวางชั้นวางสินค้า (Shelf Management) เท่านั้น แต่ยังช่วยในการทำระบบแนะนำสินค้า (Recommendation System) และการจัดโปรโมชันแบบแพ็กคู่ (Bundling) อีกด้วย [1]
12.10 Market Basket Analysis (การวิเคราะห์ตะกร้าสินค้า)
หัวใจของกฏความสัมพันธ์ คือการหาความสัมพันธ์ในรูปแบบ “If-Then” (ถ้า… แล้ว…) \(\{ \text{เหตุ} \} \rightarrow \{ \text{ผล} \}\) > เช่น: \(\{ \text{ขนมปัง, นม} \} \rightarrow \{ \text{เนย} \}\)
หมายความว่า “ถ้าลูกค้าซื้อขนมปังและนม มีแนวโน้มสูงที่เขาจะหยิบเนยลงตะกร้าไปด้วย”
12.11 มาตรวัดความแกร่งของกฎความสัมพันธ์
นักวิทยาศาสตร์ข้อมูลข้อมูลต้องมี “ไม้บรรทัด” 3 ชิ้นเพื่อตัดสินว่ากฎที่ค้นพบนั้นเป็น “ของจริง” หรือ “แค่เรื่องบังเอิญ” ในการพิจารณากฎความสัมพันธ์ \(A \rightarrow B\) (โดยที่ \(A\) คือเหตุ/Antecedent และ \(B\) คือผล/Consequent) เราจะใช้มาตรวัดทางคณิตศาสตร์ 3 ตัวหลักในการตัดสินดังนี้
1. Support (ความบ่อย) คือ สัดส่วนของธุรกรรม (Transactions) ทั้งหมดที่มีทั้งสินค้า \(A\) และ \(B\) เกิดขึ้นร่วมกัน ใช้เพื่อวัดความ “แมส” หรือความนิยมของกฎนี้
สูตร: \[Support(A \rightarrow B) = P(A \cap B) = \frac{\text{จำนวนตะกร้าที่มีทั้ง A และ B}}{\text{จำนวนตะกร้าทั้งหมด}}\]
ความสำคัญ: ช่วยคัดกรองกฎที่เป็น “Niche” เกินไปออกไป หากค่า Support ต่ำเกินไป แม้กฎจะแม่นยำแค่ไหน ก็อาจไม่คุ้มค่าในเชิงเศรษฐศาสตร์ที่จะนำไปทำแคมเปญ
2. Confidence (ความเชื่อมั่น) คือ ความน่าจะเป็นที่ลูกค้าจะซื้อ \(B\) เมื่อทราบว่าเขาได้ซื้อ \(A\) ไปแล้ว (Conditional Probability) ใช้เพื่อวัดความ “แม่นยำ” ของกฎ
สูตร: \[\begin{aligned}Confidence(A \rightarrow B) &= P(B|A) = \frac{Support(A \cap B)}{Support(A)}\nonumber\\ &= \frac{\text{จำนวนตะกร้าที่มีทั้ง A และ B}}{\text{จำนวนตะกร้าที่มี A}}\end{aligned}\]
ความสำคัญ: บ่งบอกความไว้ใจได้ของกฎ เช่น Confidence = 0.8 หมายความว่า “ในบรรดาคนที่ซื้อ A ทั้งหมด มีถึง 80% ที่ซื้อ B ตามไปด้วย”
3. Lift (แรงจูงใจ) คือ มาตรวัดที่บอกว่าการเกิด \(A\) และ \(B\) ร่วมกันนั้น “ดีกว่าการสุ่ม” หรือไม่ โดยเปรียบเทียบความเชื่อมั่นของกฎกับความน่าจะเป็นทั่วไปของสินค้า \(B\)
สูตร: \[\begin{aligned} Lift(A \rightarrow B) &= \frac{Confidence(A \rightarrow B)}{Support(B)} \nonumber\\ &= \frac{P(A \cap B)}{P(A) \cdot P(B)}\end{aligned}\]
การแปลผล:
\(Lift > 1\): สินค้า \(A\) และ \(B\) ส่งเสริมกัน (Positive Correlation) การซื้อ \(A\) ช่วย “ดึงดูด” ให้เกิดการซื้อ \(B\) มากกว่าปกติ
\(Lift = 1\): สินค้าทั้งสองเป็นอิสระต่อกัน (Independence) การที่เห็นซื้อคู่กันเป็นเพียงเรื่องบังเอิญตามดวง
\(Lift < 1\): สินค้าทั้งสองขัดแย้งกัน (Negative Correlation) การซื้อ \(A\) อาจทำให้โอกาสซื้อ \(B\) “ลดลง” (เช่น สินค้าที่ใช้ทดแทนกันได้) [7]
ลองจินตนาการว่า ‘ข้าวเปล่า’ เป็นสินค้าที่ใครๆ ก็ซื้อ (Support สูงมาก) ถ้าเราสร้างกฎ \(\{ \text{ไข่เจียว} \} \rightarrow \{ \text{ข้าวเปล่า} \}\) เราอาจจะได้ค่า Confidence สูงถึง 99% แต่นั่นไม่ได้หมายความว่าไข่เจียวเป็นตัวดึงดูดข้าวเปล่า เพราะไม่ว่าซื้ออะไร คนก็ซื้อข้าวเปล่าอยู่ดี!
แต่ถ้าเราเจอกฎ \(\{ \text{ไวน์ขาว} \} \rightarrow \{ \text{หอยนางรม} \}\) แม้ค่า Confidence จะแค่ 40% แต่ถ้าค่า Lift สูงถึง 5.0 นั่นแสดงว่าคนซื้อไวน์ขาวมีโอกาสซื้อหอยนางรม มากกว่าคนทั่วไปถึง 5 เท่า! นี่แหละคือ ‘กฎทองคำ’ ที่นักการตลาดโหยหา”
12.12 ตัวอย่างคลาสสิก: “เบียร์กับผ้าอ้อม” (Beer and Diapers)
ห้างค้าปลีกแห่งหนึ่งในสหรัฐฯ พบกฎความสัมพันธ์ที่ประหลาดว่า “ในช่วงเย็นวันศุกร์ คุณพ่อบ้านที่มาซื้อผ้าอ้อม มักจะหยิบเบียร์ติดมือไปด้วย”
การนำไปใช้: เมื่อรู้กฎนี้ ห้างจึงลองเอาเบียร์มาวางใกล้ๆ กับโซนผ้าอ้อม หรือจัดโปรโมชันคู่กัน ผลคือยอดขายพุ่งสูงขึ้นอย่างรวดเร็ว นี่คือพลังของการค้นพบ Pattern ที่ซ่อนอยู่ในข้อมูลโดยที่เราไม่ได้ตั้งสมมติฐานไว้ก่อน
สำหรับกฏความสัทพันธ์ อัลกอริทึมที่เป็นมาตรฐานและนักศึกษาควรเข้าใจกลไกการทำงานมากที่สุดคือ Apriori Algorithm เพราะมันแสดงให้เห็นถึงความฉลาดในการ “ตัดกิ่ง” (Pruning) ข้อมูลที่ไม่จำเป็นออกเพื่อประหยัดทรัพยากรเครื่อง
12.12.1 ขั้นตอนการทำงานของ Apriori Algorithm
หัวใจของ Apriori คือหลักการที่ว่า “ถ้าเซตของสินค้าใดไม่ผ่านเกณฑ์ความถี่ขั้นต่ำ (Minimum Support) เซตสินค้าที่มีสินค้านั้นเป็นส่วนประกอบก็ย่อมไม่ผ่านเกณฑ์เช่นกัน”
graph TD
%% Style Definitions
classDef startend fill:#a55eea,stroke:#8854d0,stroke-width:2px,color:white;
classDef process fill:#d1d8e0,stroke:#2d98da,stroke-width:2px,color:black;
classDef decision fill:#ffe0b2,stroke:#e67e22,stroke-width:2px,color:black;
classDef pruning fill:#fc5c65,stroke:#eb3b5a,stroke-width:2px,color:white;
%% Workflow
Start([START: ข้อมูล Transaction]) --> SetMin[1. กำหนดค่า Minimum Support<br/>และ Minimum Confidence]:::process
SetMin --> Scan[2. นับความถี่ของสินค้าแต่ละชิ้น<br/>Candidate Itemsets]:::process
Scan --> Prune{3. ความถี่ผ่านเกณฑ์<br/>Min Support หรือไม่?}:::decision
Prune -- "ไม่ผ่าน" --> Cut[ตัดทิ้ง Pruning<br/>ไม่นำไปรวมกลุ่มต่อ]:::pruning
Prune -- "ผ่าน" --> Join[4. จับคู่สินค้าที่ผ่านเกณฑ์<br/>เพื่อสร้างกลุ่มที่ใหญ่ขึ้น]:::process
Join --> Repeat{5. ยังสร้างกลุ่มที่<br/>ใหญ่ขึ้นได้อีกหรือไม่?}:::decision
Repeat -- "ได้" --> Scan
Repeat -- "ไม่ได้" --> GenRules[6. สร้างกฎความสัมพันธ์<br/>Association Rules]:::process
GenRules --> Filter[7. คัดเลือกกฎที่ค่า<br/>Confidence และ Lift ผ่านเกณฑ์]:::process
Filter --> Finish([FINISH: ได้กฎทองคำที่ใช้งานได้])
class Start,Finish startend;
ลองจินตนาการว่าถ้าเรามีสินค้า 1,000 ชิ้นในห้าง การจับคู่ทุกรูปแบบที่เป็นไปได้จะใช้พลังประมวลผลมหาศาลมาก อัลกอริทึม Apriori ฉลาดตรงที่มันใช้หลักการ ‘Pruning’ หรือการตัดกิ่งไม้ที่ตายแล้วทิ้งไปตั้งแต่เนิ่นๆ ถ้าสินค้าชิ้นเดียวคนยังไม่ค่อยซื้อ การเอาไปจับคู่กับอะไรมันก็ย่อมไม่ผ่านเกณฑ์อยู่ดี วิธีนี้จึงช่วยให้เราหา ‘กฎทองคำ’ ได้อย่างรวดเร็วท่ามกลางข้อมูลมหาศาล”
12.13 กรณีศึกษา: ค้นหากฎทองคำจากตะกร้าสินค้า (Market Basket Analysis)
ในปฏิบัติการนี้ เราจะสวมบทบาทเป็นผู้จัดการของร้านขายของชำ ที่ต้องการจัดชั้นวางสินค้าใหม่ เราจะใช้ชุดข้อมูล Groceries เพื่อหาว่าสินค้าชนิดใดที่ลูกค้ามักจะหยิบติดมือไปพร้อมกัน [8]
ขั้นตอนที่ 1: เตรียมพยานหลักฐาน (Data Loading)
นักศึกษาสามารถ download ข้อมูลได้จาก GOOGLEDRIVE: ch12/groceries_dataset.csv
| frankfurter | sausage | liver loaf | ham | meat |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
แสดง 10 อันดับสินค้าขายดี
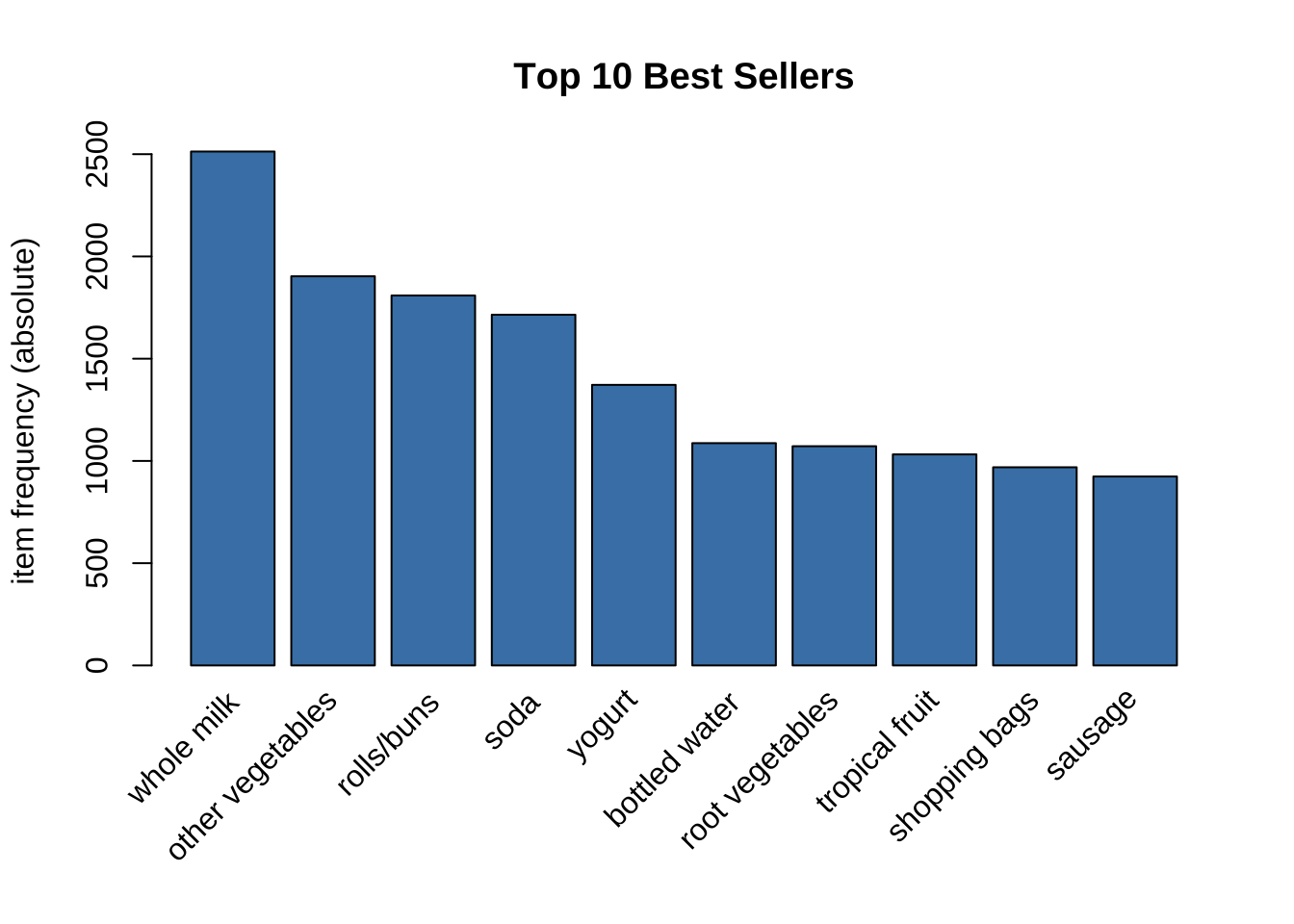
ขั้นตอนที่ 2: การหากฎความสัมพันธ์ด้วย Apriori
เราจะกำหนดเกณฑ์ขั้นต่ำ (Thresholds) เพื่อกรองเฉพาะกฎที่น่าสนใจออกมา และจัดลำดับกฎที่มีค่า Lift สูงสุดไว้สำหรับวิเคราะห์
Apriori
Parameter specification:
confidence minval smax arem aval originalSupport maxtime support minlen
0.5 0.1 1 none FALSE TRUE 5 0.001 1
maxlen target ext
10 rules TRUE
Algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
Absolute minimum support count: 9
set item appearances ...[0 item(s)] done [0.00s].
set transactions ...[169 item(s), 9835 transaction(s)] done [0.00s].
sorting and recoding items ... [157 item(s)] done [0.00s].
creating transaction tree ... done [0.00s].
checking subsets of size 1 2 3 4 5 6 done [0.00s].
writing ... [5668 rule(s)] done [0.00s].
creating S4 object ... done [0.00s].ขั้นตอนที่ 3: คัดเลือกและจัดลำดับ “กฎทองคำ”
ในบรรดากฎที่พบ เราจะใช้ฟังก์ชัน inspect เพื่อพิจารณารายละเอียดของกฎที่มีความสัมพันธ์ทรงพลังที่สุด (High Lift) เพื่อนำไปวางแผนกลยุทธ์ต่อไป
| LHS (เหตุ) | RHS (ผล) | Supp. | Confi. | Cover. | Lift | Count |
|---|---|---|---|---|---|---|
| {Instant food products,soda} | {hamburger meat} | 0.001 | 0.632 | 0.002 | 18.996 | 12 |
| {soda,popcorn} | {salty snack} | 0.001 | 0.632 | 0.002 | 16.698 | 12 |
| {flour,baking powder} | {sugar} | 0.001 | 0.556 | 0.002 | 16.408 | 10 |
| {ham,processed cheese} | {white bread} | 0.002 | 0.633 | 0.003 | 15.045 | 19 |
| {whole milk,Instant food products} | {hamburger meat} | 0.002 | 0.500 | 0.003 | 15.038 | 15 |
| {other vegetables,curd,yogurt,whipped/sour cream} | {cream cheese } | 0.001 | 0.588 | 0.002 | 14.834 | 10 |
| {processed cheese,domestic eggs} | {white bread} | 0.001 | 0.524 | 0.002 | 12.444 | 11 |
| {tropical fruit,other vegetables,yogurt,white bread} | {butter} | 0.001 | 0.667 | 0.002 | 12.031 | 10 |
| {hamburger meat,yogurt,whipped/sour cream} | {butter} | 0.001 | 0.625 | 0.002 | 11.279 | 10 |
| {tropical fruit,other vegetables,whole milk,yogurt,domestic eggs} | {butter} | 0.001 | 0.625 | 0.002 | 11.279 | 10 |
ขั้นตอนที่ 4: การแสดงผลด้วยภาพ การดูกฎเป็นข้อความอาจจะยากสำหรับผู้บริหาร เราจะวาดกราฟเครือข่าย (Network Graph) เพื่อให้เห็นพฤติกรรมลูกค้า
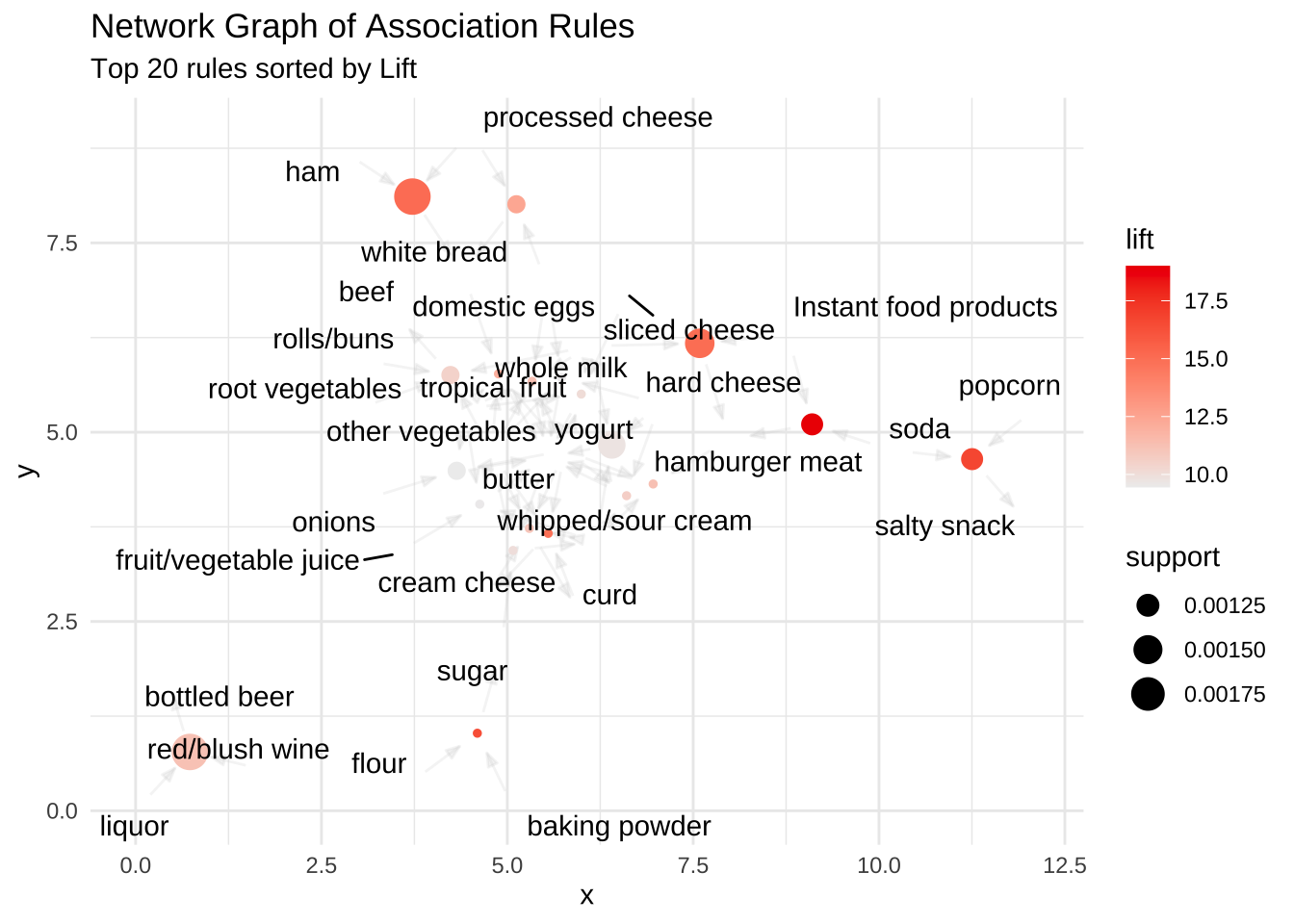
12.14 สรุปปิดท้ายบทเรียน
- เราเริ่มจากการจัดกลุ่ม ดอกไม้ Iris ด้วย K-Means เพื่อเรียนรู้การหา ‘จุดศูนย์กลาง’ ของพยานหลักฐาน
- เราเดินทางไปแอนตาร์กติกาเพื่อจำแนก นกเพนกวิน ด้วย Hierarchical Clustering ซึ่งทำให้เราเห็น ‘สายสัมพันธ์ลำดับชั้น’ จากแผนภูมิ Dendrogram
- และสุดท้าย เราวิเคราะห์ ตะกร้าสินค้า ด้วยกฏความสัมพันธ์ เพื่อค้นหา ‘กฎทองคำ’ ที่ซ่อนอยู่ในพฤติกรรมการซื้อของผู้บริโภค
ทั้งหมดนี้คือเครื่องมือที่ช่วยให้เรา ‘ฟังเสียงที่ซ่อนอยู่’ ของข้อมูลได้โดยไม่ต้องมีใครบอกเฉลยล่วงหน้า หน้าที่ของพวกคุณคือการนำ Pattern เหล่านี้ไปสร้างมูลค่าเพิ่มให้กับธุรกิจ ไม่ว่าจะเป็นการเพิ่มยอดขาย หรือการทำความเข้าใจพฤติกรรมมนุษย์ให้ลึกซึ้งยิ่งขึ้น
12.15 แบบฝึกหัดท้ายบท
ข้อที่ 1: ในการหาจำนวนกลุ่ม (\(K\)) ที่เหมาะสมที่สุดด้วยเทคนิค Elbow Method ในโปรแกรม Orange Data Mining นักศึกษาควรสังเกตการเปลี่ยนแปลงของค่าใดในกราฟ?
\(~~~\)ก. ค่า Silhouette Score ที่สูงที่สุด
\(~~~\)ข. ค่าความแปรปรวนภายในกลุ่ม (Inertia/SSE) ที่เริ่มลดลงในอัตราที่น้อยลงอย่างเห็นได้ชัด
\(~~~\)ค. จำนวนตัวแปร (Features) ที่ลดลง
\(~~~\)ง. ความสูงของเส้นกิ่งก้านใน Dendrogram
ข้อที่ 2: หากนักศึกษาต้องการตรวจสอบว่าจุดข้อมูลใดใน Orange Data Mining ที่อาจถูกจัดกลุ่มผิด (Misclassified) หรืออยู่ “ก้ำกึ่ง” ระหว่างกลุ่ม ควรใช้ Widget ใดในการตรวจสอบ?
\(~~~\)ก. Data Table
\(~~~\)ข. Silhouette Plot
\(~~~\)ค. Distributions
\(~~~\)ง. Correlations
ข้อที่ 3: เพราะเหตุใดการทำข้อมูลให้เป็นมาตราฐาน ด้วย Widget ‘Preprocess’ จึงมีความสำคัญอย่างยิ่งก่อนการทำ K-means?
\(~~~\)ก. เพื่อให้ข้อมูลที่เป็นตัวอักษรกลายเป็นตัวเลข
\(~~~\)ข. เพื่อลดขนาดไฟล์ข้อมูลให้เล็กลง
\(~~~\)ค. เพื่อป้องกันไม่ให้ตัวแปรที่มีหน่วยวัดขนาดใหญ่ (เช่น รายได้หลักหมื่น) มีน้ำหนักเหนือตัวแปรที่มีหน่วยวัดขนาดเล็ก (เช่น อายุ)
\(~~~\)ง. เพื่อให้ข้อมูลมีการกระจายตัวแบบปกติ (Normal Distribution)
ข้อที่ 4: แผนภูมิที่เป็นเอกลักษณ์ของ Hierarchical Clustering ซึ่งแสดงลำดับการรวมตัวของพยานหลักฐานจากจุดเล็กๆ จนกลายเป็นกลุ่มใหญ่เรียกว่าอะไร?
\(~~~\)ก. Scatter Plot
\(~~~\)ข. Box Plot
\(~~~\)ค. Dendrogram
\(~~~\)ง. Heatmap
ข้อที่ 5: ใน Widget ‘Hierarchical Clustering’ หากนักศึกษาเลือกใช้ Ward’s Method ผลลัพธ์ที่ได้มักจะมีลักษณะอย่างไร?
\(~~~\)ก. กลุ่มข้อมูลจะถูกลากต่อกันเป็นเส้นยาวเหมือนโซ่ (Chaining Effect)
\(~~~\)ข. กลุ่มข้อมูลที่ได้มักจะมีขนาด (Member size) ที่ค่อนข้างสมดุลและมีความแน่นแฟ้นสูง
\(~~~\)ค. จะได้จำนวนกลุ่มเท่ากับจำนวนแถวของข้อมูลเสมอ
\(~~~\)ง. ระยะห่างจะถูกคำนวณจากจุดที่ไกลที่สุดของสองกลุ่มเสมอ
ข้อที่ 6: ข้อใดคือความแตกต่างที่ชัดเจนที่สุดระหว่าง K-means และ Hierarchical Clustering?
\(~~~\)ก. K-means ใช้กับข้อมูลตัวเลขเท่านั้น ส่วน Hierarchical ใช้ได้เฉพาะตัวอักษร
\(~~~\)ข. K-means ต้องกำหนดจำนวนกลุ่มล่วงหน้า ส่วน Hierarchical สามารถมาเลือกจุดตัดกลุ่มในภายหลังได้
\(~~~\)ค. Hierarchical Clustering ประมวลผลได้เร็วกว่า K-means เมื่อข้อมูลมีขนาดใหญ่มาก (Big Data)
\(~~~\)ง. K-means ให้ผลลัพธ์เป็นโครงสร้างต้นไม้เสมอ
ข้อที่ 7: ค่า Support ในการวิเคราะห์ตะกร้าสินค้า หมายถึงข้อใด?
\(~~~\)ก. ความเชื่อมั่นว่าถ้าซื้อสินค้า A แล้วจะซื้อ B ตามมา
\(~~~\)ข. ความถี่หรือร้อยละที่ชุดสินค้านั้นๆ ปรากฏขึ้นในรายการธุรกรรมทั้งหมด
\(~~~\)ค. มาตรวัดที่บอกว่ากฎนั้นดีกว่าการเดาสุ่มกี่เท่า
\(~~~\)ง. จำนวนเงินรวมที่ลูกค้าจ่ายในแต่ละครั้ง
ข้อที่ 8: หากกฎความสัมพันธ์ระบุว่า \(\{ \text{ขนมปัง} \} \rightarrow \{ \text{นม} \}\) มีค่า Confidence = 0.8 หมายความว่าอย่างไร?
\(~~~\)ก. ในบรรดาการซื้อทั้งหมด มี 80% ที่ซื้อทั้งขนมปังและนม
\(~~~\)ข. ในบรรดาคนที่ซื้อนม มี 80% ที่ซื้อขนมปังด้วย
\(~~~\)ค. ในบรรดาคนที่ซื้อขนมปัง มี 80% ที่ซื้อนมติดมือไปด้วย
\(~~~\)ง. การซื้อขนมปังช่วยเพิ่มโอกาสการซื้อนมขึ้น 80 เท่า
ข้อที่ 9: มาตรวัดใดที่เป็น “หัวใจสำคัญ” ในการยืนยันว่าสินค้าสองชนิดมีความสัมพันธ์เชิงบวกต่อกันจริงๆ (ไม่ได้เกิดจากความบังเอิญ)?
\(~~~\)ก. ค่า Support ที่สูงที่สุด
\(~~~\)ข. ค่า Lift ที่มีค่ามากกว่า 1
\(~~~\)ค. ค่า Lift ที่มีค่าเท่ากับ 1
\(~~~\)ง. จำนวน Count ที่มากที่สุด
ข้อที่ 10: ในโปรแกรม Orange หากข้อมูลตั้งต้นเป็นตารางรายชื่อลูกค้าและพฤติกรรม (เช่น อายุ, เพศ, อาชีพ) ก่อนจะนำไปเข้า Widget ‘Association Rules’ นักศึกษาควรทำสิ่งใดก่อน?
\(~~~\)ก. ทำการ Discretize เพื่อเปลี่ยนตัวเลขต่อเนื่อง (เช่น อายุ) ให้เป็นช่วงกลุ่ม (Categorical)
\(~~~\)ข. ทำการลบข้อมูลลูกค้าที่ซ้ำกันออกทั้งหมด
\(~~~\)ค. ทำการหาค่าเฉลี่ยของข้อมูลทั้งหมด
\(~~~\)ง. ใช้ Widget ‘PCA’ เพื่อลดมิติข้อมูล