9 สถิติสำหรับนักวิเคราะห์ข้อมูล
ในบทที่ผ่านมา เราได้เรียนรู้เรื่อง ความน่าจะเป็น (Probability) ซึ่งเปรียบเสมือนการทำงานในโลกที่มีข้อมูลสมบูรณ์หรือมี “กฎ” ที่แน่นอนรองรับ (เช่น เรารู้ว่าเหรียญมี 2 หน้า หรือรู้ว่าประชากรทั้งหมดมีลักษณะอย่างไร) เราจึงใช้ทฤษฎีเพื่อ “ทำนาย” ผลลัพธ์ที่ควรจะเป็น
แต่ในบทนี้ สถิติสำหรับนักวิเคราะห์ข้อมูล เราจะทำงานในทิศทางตรงกันข้าม
ความเป็นจริงของข้อมูล: ในโลกของข้อมูลขนาดใหญ่ ข้อมูลยากที่จะสมบูรณ์ มีการกระจัดกระจาย และเต็มไปด้วยสัญญาณรบกวน (Noise)
บทบาทนักวิเคราะห์: เราจะสวมบทบาทเป็น “นักพิสูจน์หลักฐาน” (Data Forensic) ที่ไม่มีทางรู้ความจริงทั้งหมด แต่ต้องใช้ “หลักฐาน” (ข้อมูลตัวอย่าง) มาทำการคำนวณและประเมินเพื่อ “สืบกลับ” ไปหาความจริงของประชากรทั้งหมด
9.1 สถิติเชิงพรรณนา: การบันทึกปากคำหลักฐาน
ก่อนจะไปฟันธงหรือตัดสินอะไร นักวิเคราะห์ต้องทำการ “สรุปภาพรวมของหลักฐาน” ให้ชัดเจนเสียก่อน โดยใช้มาตรวัดที่ช่วยให้เราเห็นจุดศูนย์กลางและความผันผวน [1]
9.1.1 การวัดค่ากลาง (Central Tendency)
ในการเริ่มต้นพิสูจน์หลักฐาน สิ่งแรกที่นักวิเคราะห์ต้องทำคือการหา “จุดยุทธศาสตร์” หรือ “พิกัดศูนย์กลาง” ของข้อมูลชุดนั้น เพื่อให้ทราบว่าโดยภาพรวมแล้ว ข้อมูลส่วนใหญ่ “ไปกองกันอยู่ที่ไหน”
เราเรียกกระบวนการนี้ว่า การวัดค่ากลาง (Measures of Central Tendency) ซึ่งเปรียบเสมือนการหา “ตัวแทนหมู่บ้าน” เพื่อมาสรุปภาพรวมของคนในหมู่บ้านที่มีความหลากหลาย
9.1.1.1 ทำไมต้องหาค่ากลาง?
ในโลกของข้อมูลขนาดใหญ่ ข้อมูลอาจมีเป็นล้านบรรทัด เราไม่สามารถอ่านข้อมูลทุกบรรทัดเพื่อสรุปผลได้ นักวิเคราะห์จึงต้องการตัวเลขเพียงค่าเดียวที่สามารถ “เป็นกระบอกเสียง” ให้กับข้อมูลทั้งหมดนั้นได้ การวัดค่ากลางช่วยให้เรา
ย่อยข้อมูล (Data Reduction): เปลี่ยนตารางตัวเลขมหาศาลให้เหลือเพียงจุดจุดเดียว
สร้างเกณฑ์อ้างอิง (Benchmarking): เพื่อใช้เปรียบเทียบว่าข้อมูลตัวอื่นๆ อยู่สูงหรือต่ำกว่ามาตรฐานกลาง
ระบุพฤติกรรมหลัก: เพื่อให้ทราบว่าแนวโน้มหลัก (Mainstream) ของเหตุการณ์นั้นๆ คืออะไร
9.1.1.2 กับดักของการเลือก “ตัวแทน”
นักวิเคราะห์ต้องระลึกไว้เสมอว่า การเลือกค่ากลางคือการเลือก “มุมมอง” ในการนำเสนอความจริง เพราะในข้อมูลชุดเดียวกัน หากเราเลือกวิธีหาค่ากลางที่ต่างกัน เราอาจจะได้ “ตัวแทน” ที่มีนิสัยต่างกันอย่างสิ้นเชิง
ตัวแทนที่เน้นความสอดคล้อง: คือการมองหาค่าที่เกิดจากความสมดุลของข้อมูลทั้งหมด
ตัวแทนที่เน้นความยุติธรรม: คือการเลือกพิกัดที่อยู่กึ่งกลางพอดี เพื่อไม่ให้ข้อมูลฝั่งใดฝั่งหนึ่ง (ซ้ายหรือขวา) มีอิทธิพลมากเกินไป
ตัวแทนที่เน้นความนิยม: คือการมองหาพฤติกรรมที่เกิดขึ้นซ้ำซากที่สุดในหมู่พยานหลักฐาน
ในฐานะนักวิทยาศาสตร์ข้อมูล คุณต้องเลือกว่าจะเชื่อใจ “ค่ากลาง” ประเภทใด โดยพิจารณาจาก “ความเรียบร้อย” ของข้อมูลเป็นหลัก
9.2 ค่าเฉลี่ย (Mean): ตัวแทนค่ากลางของข้อมูล
ค่าเฉลี่ยเปรียบเสมือนพยานที่นำทุกความเห็น (ทุกค่าข้อมูล) มาหลอมรวมกันแล้วหาจุดสมดุล
จุดแข็ง: เป็นพยานที่ละเอียดที่สุด เพราะนำข้อมูลทุกตัวมาคำนวณ ไม่ทิ้งใครไว้ข้างหลัง
เงื่อนไขการใช้งาน: เหมาะสำหรับหลักฐานที่ “เกาะกลุ่มเป็นระเบียบ” และมีความสมมาตร (ไม่มีใครแปลกแยกจากกลุ่มมากเกินไป)
Business Insight: หากยอดซื้อกาแฟของลูกค้าส่วนใหญ่อยู่ในช่วง 60-80 บาท ค่าเฉลี่ยจะเป็นตัวเลขที่แม่นยำมากในการวางแผนสต็อกวัตถุดิบ [2]
เนื่องจากการหาค่าเฉลี่ยต้องใช้การ ‘บวก’ ข้อมูลทุกตัว (\(\sum x\)) เข้าไปด้วยกัน ดังนั้นถ้ามีข้อมูลตัวใดตัวหนึ่งมีค่า ‘สูงผิดปกติ’ (Outlier) โผล่เข้ามาเพียงตัวเดียว มันจะเข้าไปดึงผลรวมให้พุ่งสูงขึ้นทันที ส่งผลให้ค่าเฉลี่ย (\(\bar{x}\)) เพี้ยนไปจากความเป็นจริง…
9.3 มัธยฐาน (Median): ค่ากลางที่ทนต่อค่าผิดปกติ
มัธยฐานคือค่าที่อยู่กึ่งกลางของข้อมูล หลังจากเรียงลำดับข้อมูลจากน้อยไปมาก หรือมากไปน้อย โดยค่าดังกล่าวจะแบ่งข้อมูลออกเป็นสองส่วนที่มีจำนวนข้อมูลเท่ากัน
จุดเด่น: มัธยฐานเป็นค่ากลางที่ได้รับผลกระทบจากค่าผิดปกติ (Outliers) น้อยกว่าค่าเฉลี่ย เนื่องจากพิจารณาเพียง “ตำแหน่ง” ของข้อมูล ไม่ได้พิจารณาขนาดของค่าที่สูงหรือต่ำผิดปกติ
เงื่อนไขการใช้งาน: เหมาะสำหรับข้อมูลที่มีการกระจายไม่สมมาตร (Skewed Distribution) หรือมีค่าผิดปกติปะปนอยู่ เช่น กรณีที่ลูกค้าส่วนใหญ่ซื้อสินค้าประมาณ 60 บาท แต่มีลูกค้าบางรายซื้อสินค้ามูลค่า 10,000 บาท ค่าเฉลี่ยอาจสูงผิดปกติ ขณะที่มัธยฐานยังคงสะท้อนพฤติกรรมของลูกค้าส่วนใหญ่ได้ดีกว่า
Business Insight: ในการวิเคราะห์รายได้ประชากรหรือเงินเดือนพนักงาน นักวิเคราะห์มักเลือกใช้มัธยฐานเพื่อป้องกันไม่ให้รายได้ของคนเพียงส่วนน้อยที่สูงมาก ส่งผลให้ภาพรวมของรายได้สูงเกินความเป็นจริง [3]
9.3.1 ️ จุดสังเกตสำหรับนักวิเคราะห์
ถ้า Mean > Median \(\rightarrow\) ข้อมูลมีการกระจายแบบ “เบ้ขวา” (มีพยานที่รวยมาก/ค่าสูงมาก มาดึงค่าเฉลี่ยไป)
ถ้า Mean < Median \(\rightarrow\) ข้อมูลมีการกระจายแบบ “เบ้ซ้าย” (มีพยานที่ค่าน้อยมาก มาดึงค่าเฉลี่ยลง)
9.4 ฐานนิยม (Mode): ค่าที่พบได้บ่อยที่สุด
ฐานนิยมคือค่าของข้อมูลที่ปรากฏซ้ำบ่อยที่สุดในชุดข้อมูล จึงเป็นตัวแทนของสิ่งที่ “พบมากที่สุด” หรือ “ได้รับความนิยมมากที่สุด” ในข้อมูลชุดนั้น
จุดเด่น: ฐานนิยมเป็นมาตรวัดแนวโน้มเข้าสู่ส่วนกลางเพียงชนิดเดียวที่สามารถใช้กับข้อมูลเชิงกลุ่ม (Categorical Data) ได้ เช่น ประเภทสินค้า สีของสินค้า ชื่อเมนูอาหาร หรือวันในสัปดาห์ ซึ่งค่าเฉลี่ยและมัธยฐานไม่สามารถนำมาใช้ได้โดยตรง
เงื่อนไขการใช้งาน: เหมาะสำหรับกรณีที่ต้องการทราบว่าค่าใดหรือกลุ่มใดได้รับความนิยมสูงสุด โดยไม่จำเป็นต้องพิจารณาลำดับหรือค่าทางตัวเลขของข้อมูล
Business Insight: ในร้าน Chiang Mai Brew การทราบว่าเมนูที่ขายดีที่สุดคือ “Iced Americano” มีความสำคัญมากกว่าการคำนวณค่าเฉลี่ยยอดขายของทุกเมนู เพราะช่วยสะท้อนพฤติกรรมและความนิยมของลูกค้าส่วนใหญ่ได้อย่างชัดเจน
| สถิติ | หน้าที่หลัก | จุดที่ควรระวัง | เหมาะกับเครื่องมือ |
|---|---|---|---|
| ค่าเฉลี่ย (Mean) | หาจุดสมดุลของข้อมูลทั้งหมด | แพ้ทาง Outliers (ถูกค่าสุดโต่งดึงให้เพี้ยนได้ง่าย) | =AVERAGE() ใน Excel |
| มัธยฐานn (Media) | หาจุดกึ่งกลางที่แบ่งข้อมูล 50/50 | ไม่สะท้อนผลรวมของมูลค่าทั้งหมด | =MEDIAN() ใน Excel |
| ฐานนิยม (Mode ) | หาพฤติกรรมยอดฮิต / กระแสหลัก | ข้อมูลบางชุดอาจ ไม่มีฐานนิยม หรือมีหลายค่า | =MODE.SNGL() ใน Excel |
หลังจากที่เราได้พยานที่เป็น “ตัวแทน” (ค่ากลาง) มาแล้ว ขั้นตอนต่อไปของนักพิสูจน์หลักฐานคือการตรวจสอบว่า “พยานแต่ละปากพูดสอดคล้องกันหรือไม่?” หรือข้อมูลมีการ กระจัดกระจาย (Dispersion) มากน้อยเพียงใด
เพราะค่าเฉลี่ยที่เท่ากัน อาจมาจากชุดข้อมูลที่มีความน่าเชื่อถือต่างกันโดยสิ้นเชิง การวัดความกระจายจึงเปรียบเสมือนการวัด “ความเสี่ยง” หรือ “ความผันผวน” ของข้อมูล
9.4.1 ทำไมต้องวัดความกระจาย?
ลองจินตนาการว่าร้าน Chiang Mai Brew กำลังทดสอบพนักงานชงกาแฟ 2 คน โดยให้ชงกาแฟที่มีน้ำหนักเนื้อกาแฟเฉลี่ย 18 กรัมเท่ากัน
พนักงาน A: ชงได้ 17.9 18.0 18.1 (ค่าเฉลี่ย 18 กระจายน้อย = คุณภาพนิ่ง)
พนักงาน B: ชงได้ 15.0 18.0 21.0 (ค่าเฉลี่ย 18 กระจายมาก = คุณภาพไม่นิ่ง)
ถ้านักวิเคราะห์ดูแค่ “ค่าเฉลี่ย” จะพบว่าทั้งคู่สอบผ่าน แต่ถ้าวัด “ความกระจาย” เราจะรู้ทันทีว่าพนักงาน B คือความเสี่ยงของร้าน
9.4.2 เครื่องมือวัดความกระจายที่สำคัญ
ในฐานะนักวิเคราะห์ข้อมูล เรามี “ไม้บรรทัด” 3 แบบที่ใช้บ่อย
9.4.2.1 พิสัย (Range)
คือส่วนต่างระหว่างค่าที่มากที่สุดและน้อยที่สุด (\(Max - Min\))
จุดแข็ง: เข้าใจง่ายที่สุด บอกขอบเขตของหลักฐาน
จุดอ่อน: อ่อนไหวต่อค่าสุดโต่ง (Outliers) มากเกินไป
9.4.2.2 ส่วนเบี่ยงเบนมาตรฐาน (Standard Deviation: SD)
คือพระเอกของงานนี้ เป็นค่าที่บอกว่า “โดยเฉลี่ยแล้ว ข้อมูลแต่ละตัวอยู่ห่างจากค่ากลาง (Mean) เท่าไหร่”
SD น้อย: ข้อมูลเกาะกลุ่มกันแน่น (มีความสม่ำเสมอสูง)
SD มาก: ข้อมูลกระจายตัวกว้าง (มีความผันผวน หรือมีความเสี่ยงสูง) [4]
ในเชิงคณิตศาสตร์: เป็นค่ารากที่สองของความแปรปรวน (Variance) เพื่อให้อยู่ในหน่วยเดียวกับข้อมูลเดิม
9.4.2.3 พิสัยระหว่างควอไทล์ (Interquartile Range: IQR)
คือความกว้างของข้อมูลกลุ่ม 50% ที่อยู่ตรงกลาง (ใช้คู่กับ Median)
- จุดแข็ง: ไม่สนใจค่าสุดโต่ง (Outliers) ที่อยู่หัวแถวหรือท้ายแถว เหมาะสำหรับวัดความกระจายของข้อมูลที่ไม่เป็นระเบียบ
การคำนวณด้วยเครื่องมือของนักวิเคราะห์
Microsoft Excel
หา SD:
=STDEV.S(ช่วงข้อมูล)(S หมายถึง Sample หรือข้อมูลตัวอย่าง)หา Range:
=MAX(ช่วงข้อมูล) - MIN(ช่วงข้อมูล)
jamovi ในเมนู Descriptives ที่เราเปิดไว้
ใต้หัวข้อ Statistics > Dispersion
ติ๊กถูกที่ช่อง Std. deviation, Range, และ IQR
โปรแกรมจะแสดงผลลัพธ์ต่อท้ายตารางค่ากลางทันที
ในโลกของนักวิเคราะห์ค่าเฉลี่ยอาจเปรียบเสมือนกำไร แต่ SD คือความเสี่ยง การที่คุณนำเสนอแผนธุรกิจที่มีค่าเฉลี่ยกำไรสูง แต่มีค่า SD ที่กว้างมาก ผู้บริหารที่เก่งเขาจะยังไม่เซ็นอนุมัติ เพราะมันบอกว่าคุณอาจจะกำไรมหาศาลหรือขาดทุนย่อยยับก็ได้ หน้าที่ของคุณคือใช้สถิติตัวนี้เพื่อ ‘ควบคุม’ ความเสี่ยงให้อยู่ในระดับที่ยอมรับได้
เมื่อเรานำพยานหลักฐานทั้งหมดมาจัดวางเรียงกันในรูปแบบของกราฟแท่งหรือ Histogram เราจะพบว่า “รูปทรง” ของมันสามารถบอกเล่าพฤติกรรมของธุรกิจได้อย่างน่าอัศจรรย์ ดังนี้
9.5 รูปแบบการกระจายข้อมูล: การเชื่อมโยงสู่ Histogram
Histogram เป็นเครื่องมือสำคัญที่ช่วยให้เราเห็นลักษณะการกระจายของข้อมูล โดยการพิจารณาความสูงของแท่งกราฟทั้งหมด ทำให้สามารถประเมินรูปแบบ ความสมมาตร ความเบ้ และความโด้งของข้อมูลได้อีกด้วย
การพิจารณารูปแบบการกระจายของข้อมูลมีความสำคัญต่อการเลือกใช้ค่ากลางและวิธีวิเคราะห์ที่เหมาะสม ตัวอย่างเช่น หากข้อมูลมีการกระจายแบบสมมาตร ค่าเฉลี่ยมักสามารถสะท้อนภาพรวมของข้อมูลได้ดี แต่หากข้อมูลมีการกระจายแบบเบ้หรือมีค่าผิดปกติ มัธยฐานอาจเป็นตัวแทนที่เหมาะสมกว่า
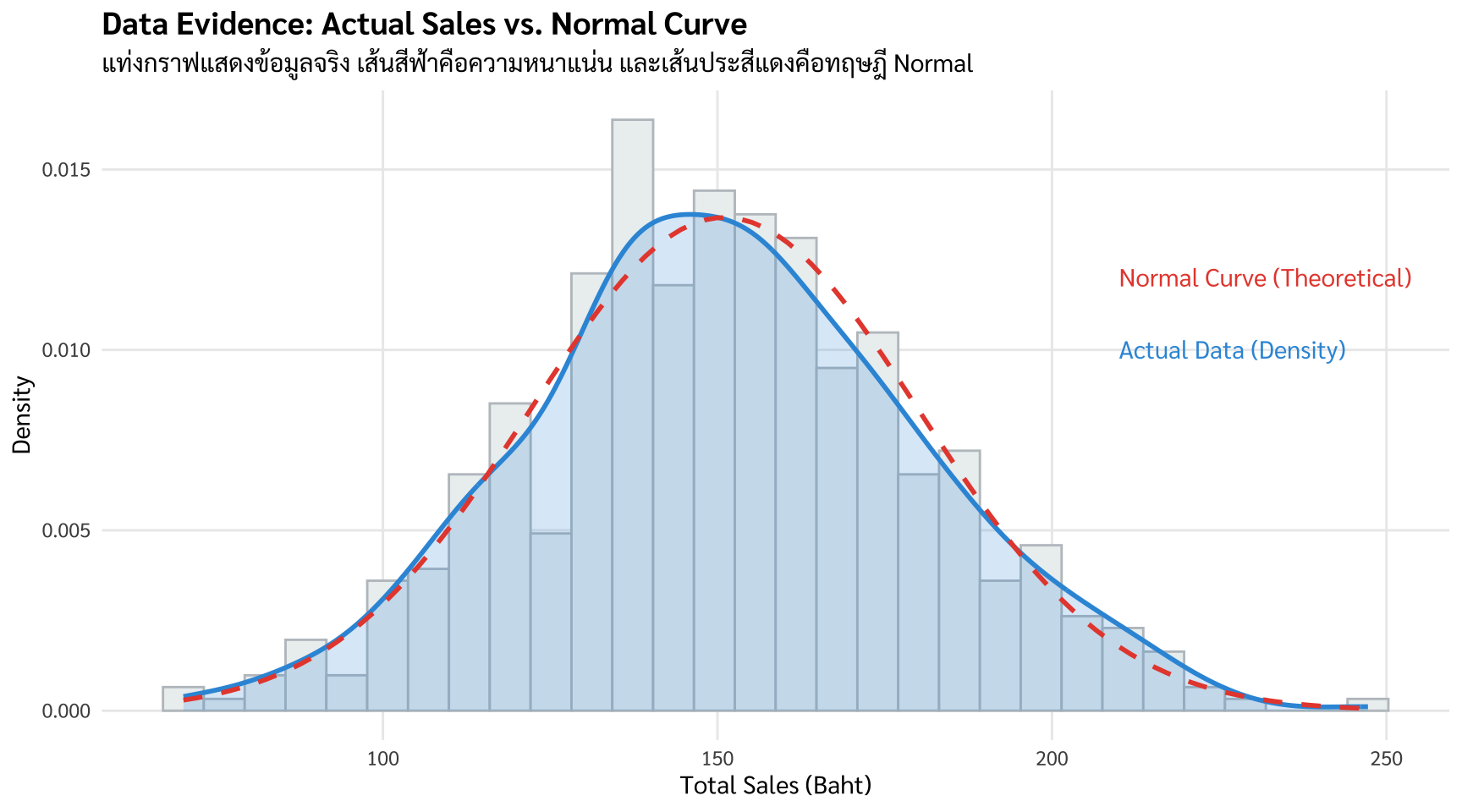
9.5.1 การแจกแจงแบบปกติ (Normal Distribution): รูปแบบการกระจายในอุดมคติ
หากข้อมูลของเรามีลักษณะสมมาตร เป็นรูป “ระฆังคว่ำ” ที่มีจุดสูงสุดอยู่ตรงกลาง
ลักษณะทางสถิติ: ค่าเฉลี่ย ค่ามัธยฐานและค่าฐานนิยมจะมีค่าเท่ากัน (หรือใกล้เคียงกันมาก)
การตีความ: ข้อมูลส่วนใหญ่เกาะกลุ่มกันอยู่ที่ค่าเฉลี่ย และกระจายออกไปด้านข้างอย่างเป็นระเบียบตามค่า SD
Business Insight: หากยอดซื้อกาแฟที่ร้านมีลักษณะการแจกแจงแบบปกติหมายความว่าคุณมีกลุ่มลูกค้าหลักที่ชัดเจน และการคาดการณ์ยอดขายในอนาคตจะมีความแม่นยำสูงมาก [2]
9.5.2 การแจกแจงที่ไม่สมมาตร: รูปแบบการกระจายที่เอียงไปด้านใดด้านหนึ่ง
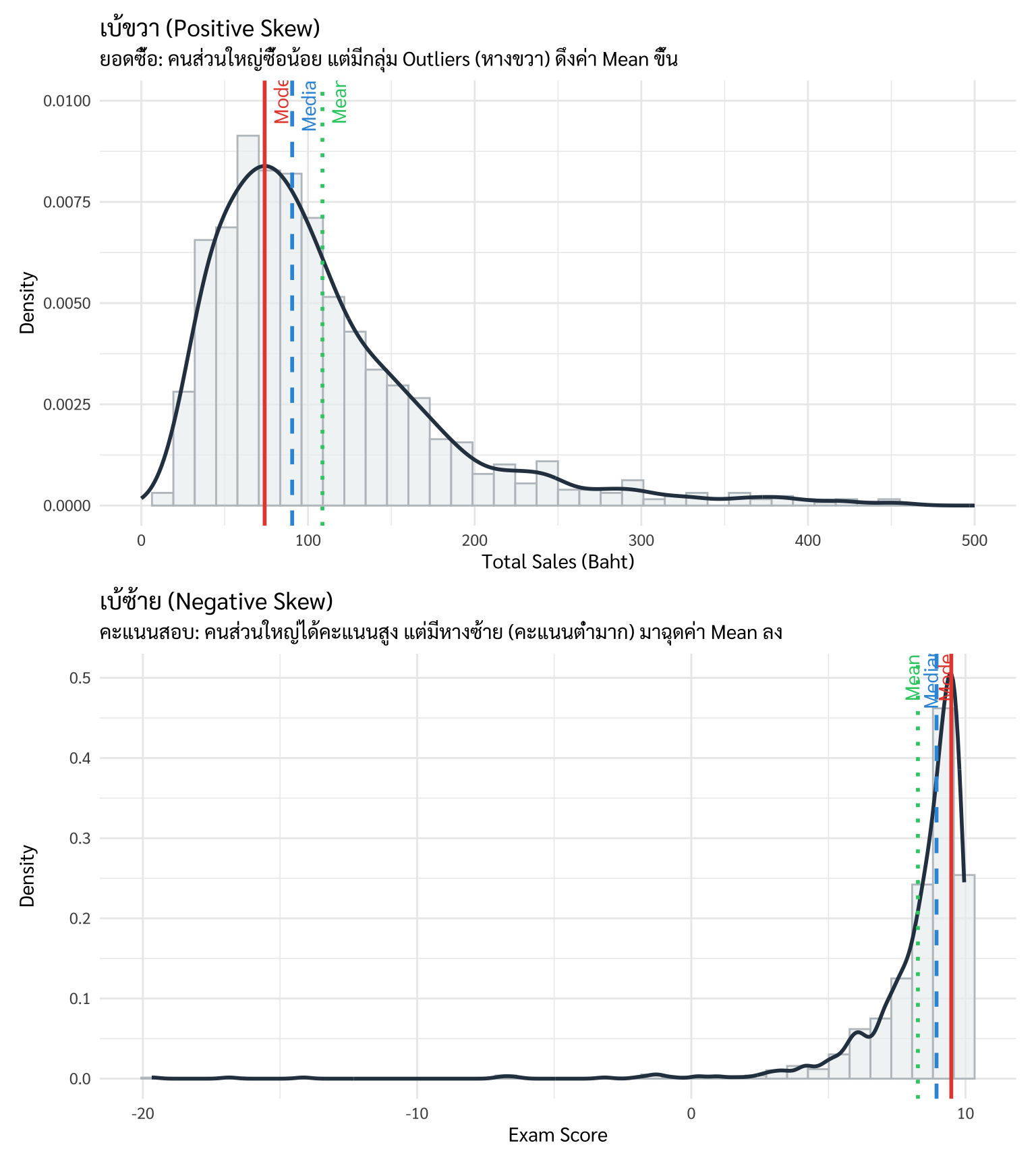
ในโลกความเป็นจริง ข้อมูลมักจะไม่เป็นระเบียบ และมี “หาง” ลากยาวไปฝั่งใดฝั่งหนึ่ง
- การเบ้ขวา (Positive Skew): หางลากยาวไปทางด้านค่าสูง (ขวามือ)
- ความสัมพันธ์: Mean > Median > Mode
- Business Insight: พบได้บ่อยในข้อมูล “รายได้” หรือ “ยอดซื้อ” คือคนส่วนใหญ่ซื้อน้อย (Mode อยู่ทางซ้าย) แต่มีลูกค้ากระเป๋าหนักเพียงไม่กี่คน (Outliers) มาดึงให้ค่าเฉลี่ยพุ่งสูงขึ้น
- การเบ้ซ้าย (Negative Skew): หางลากยาวไปทางด้านค่าน้อย (ซ้ายมือ)
- ความสัมพันธ์: Mean < Median < Mode
- Business Insight: เช่น คะแนนสอบของนักศึกษาในวิชาที่ง่ายเกินไป คนส่วนใหญ่ได้คะแนนสูง แต่มีบางคนที่ได้คะแนนน้อยมากมาฉุดค่าเฉลี่ยลง
9.5.3 9.5 กฎ 68-95-99.7 (Empirical Rule) กับการวัดความเสี่ยง
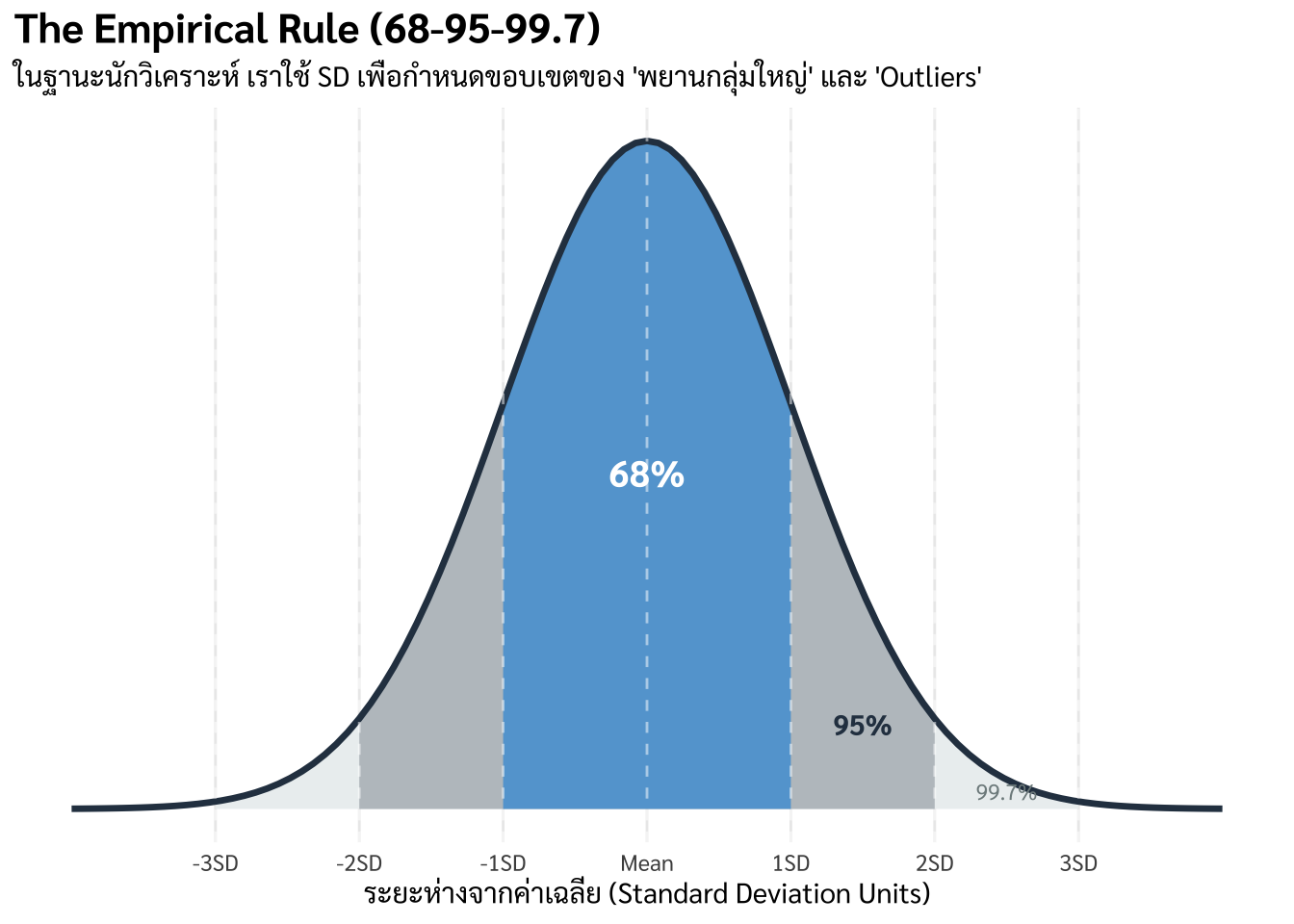
เมื่อข้อมูลมีการแจกแจงแบบปกติ เราสามารถใช้ SD เป็นไม้บรรทัดวัดความเชื่อมั่นได้ทันที
\(\pm 1\) SD: จะครอบคลุมข้อมูลประมาณ 68% (กลุ่มลูกค้าปกติ)
\(\pm 2\) SD: จะครอบคลุมข้อมูลประมาณ 95% (เกือบทุกคนในร้าน)
\(\pm 3\) SD: จะครอบคลุมข้อมูลถึง 99.7% (หากใครหลุดจากช่วงนี้ไป เขาคือพยานที่ “ประหลาด” หรือ Outlier อย่างชัดเจน)
หลังจากที่นักวิเคราะห์ได้ทำหน้าที่ “นักพิสูจน์หลักฐาน” เพื่อหาค่ากลาง (ค่าเฉลี่ย) และความกระจาย (SD) ของข้อมูลชุดต่างๆ เรียบร้อยแล้ว คำถามสำคัญถัดมาที่ฝ่ายบริหารมักจะถามเราคือ “แล้วเราควรเลือกทางไหน?”
ในโลกของนักวิเคราะห์ข้อมูล การตัดสินใจไม่ได้ใช้เพียง “ความรู้สึก” (Gut Feeling) แต่เราใช้หลักการที่เรียกว่า Mean-Variance Criteria เพื่อเปรียบเทียบความคุ้มค่าและความเสี่ยงอย่างเป็นรูปธรรม
Mean (ผลตอบแทน): คือ “เป้าหมาย” หรือผลลัพธ์โดยเฉลี่ยที่เราคาดหวังจะได้รับ
Variance/SD (ความเสี่ยง): คือ “ความไม่แน่นอน” หรือโอกาสที่ผลลัพธ์จริงจะกระเด็นออกห่างจากเป้าหมายที่เราวางไว้
การใช้หลักการนี้จะช่วยให้นักวิเคราะห์สามารถคัดกรองตัวเลือกที่ “ดีกว่าในทุกมิติ” (Dominance) ออกมาได้อย่างชัดเจน
9.6 การตัดสินใจด้วยสถิติ: หลักการ Mean-Variance Criteria
ในการดำเนินธุรกิจ นักวิเคราะห์มักต้องเผชิญกับทางเลือกหลายทาง (เช่น จะลงโฆษณาใน Facebook หรือ TikTok ดี? หรือจะขยายสาขาไปที่นิมมานฯ หรือหลัง มช. ดี?)
Mean-Variance Criteria คือกฎการตัดสินใจที่ใช้ตัวเลขสถิติ 2 ตัวมาคานอำนาจกัน:
Mean (\(\mu\)): แทน “ผลตอบแทนคาดหวัง” (ยิ่งมากยิ่งดี)
Variance (\(\sigma^2\)) หรือ SD (\(\sigma\)): แทน “ความเสี่ยงหรือความผันผวน” (ยิ่งน้อยยิ่งดี)
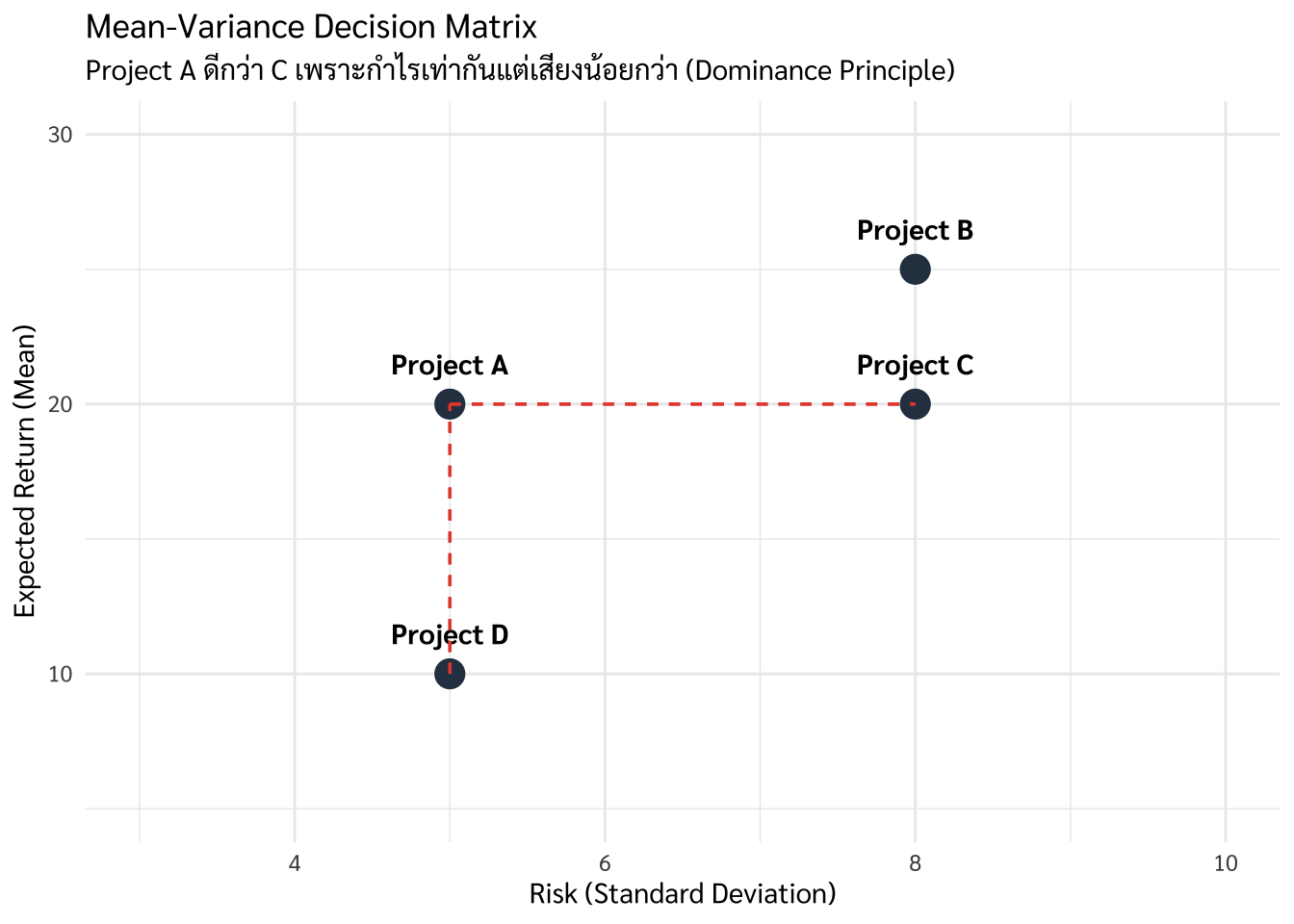
9.6.1 กรณีศึกษา: การเลือกทำเลสาขาใหม่ของ Chiang Mai Brew
จงช่วยวิเคราะห์ข้อมูลยอดขายที่คาดการณ์ของ 2 ทำเล
| ทำเล (Location) | ยอดขายเฉลี่ยต่อวัน (Mean) | ความผันผวน (SD) |
|---|---|---|
| สาขานิมมานเหมินท์ | 15,000 บาท | 2,000 บาท |
| สาขาหลัง มช. | 15,000 บาท | 5,000 บาท |
การวิเคราะห์เชิงสถิติ: แม้ทั้งสองทำเลจะมี Mean เท่ากันที่ 15,000 บาท แต่นักวิเคราะห์ที่เก่งจะเลือก สาขานิมมานฯ เพราะมีค่า SD ต่ำกว่า (ความเสี่ยงน้อยกว่า ยอดขายสม่ำเสมอทุกวัน ทำให้บริหารสต็อกง่ายกว่า) [3]
เพื่อให้เห็นภาพการตัดสินใจ เรามักใช้กราฟที่แกนหนึ่งเป็นความเสี่ยง และอีกแกนหนึ่งเป็นผลตอบแทน
9.7 ก้าวต่อไปของการวัดความเสี่ยง: สู่มูลค่าความเสี่ยง (Value at Risk: VaR)
เมื่อเราทราบแล้วว่าค่าเฉลี่ยและ SD มีข้อจำกัดในข้อมูลที่มีการกระจายแบบไม่สมมาตร นักวิเคราะห์จึงต้องใช้เครื่องมือดีกว่าเดิมในการวัดความเสียหายสูงสุดที่อาจจะเกิดขึ้น ซึ่งนั่นคือมูลค่าความเสี่ยง (VaR)
Tipมูลค่าความเสี่ยง (VaR) คือการตอบคำถามผู้บริหารที่ว่า
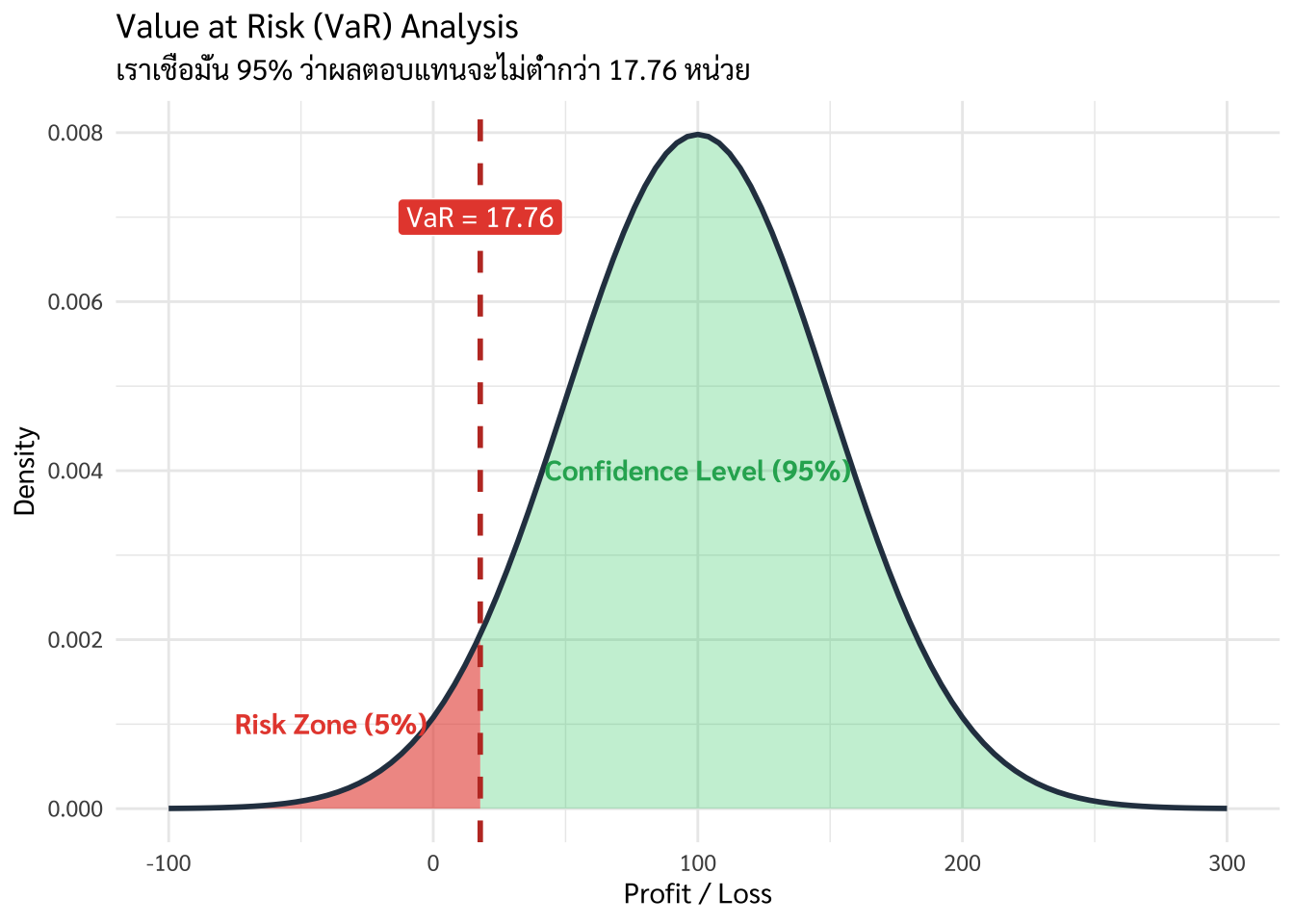
“ในสภาวะปกติ (เช่น 95% ของช่วงเวลา) ความเสียหาย ‘ที่แย่ที่สุด’ (Worst Case Scenario) ที่เราอาจจะเจอคือเท่าไหร่?
9.7.1 การเชื่อมโยงจากการแจกแจงแบบปกติสู่มูลค่าความเสี่ยง
หากเรายอมรับว่าข้อมูลมีการแจกแจงแบบปกติ เราสามารถใช้ค่า Z-score มาคำนวณหาจุดตัดความเสี่ยงได้ทันที
ช่วงความเชื่อมั่น 95%: เราจะดูที่ค่าเฉลี่ยลบออกด้วย \(1.65\) เท่าของ SD
ช่วงความเชื่อมั่น 99%: เราจะดูที่ค่าเฉลี่ยลบออกด้วย \(2.33\) เท่าของ SD
ตัวอย่าง: หากร้าน Chiang Mai Brew มียอดขายเฉลี่ย 10,000 บาท (SD = 2,000) ค่า VaR ที่ระดับความเชื่อมั่น 95% คือยอดขายที่อาจตกลงไปเหลือเพียง \(10,000 - (1.65 \times 2,000) = 6,700\) บาท
Insight: นักวิเคราะห์จะบอกผู้บริหารว่า เรามั่นใจ 95% ว่ายอดขายจะไม่ต่ำกว่า 6,700 บาท แต่คุณต้องเตรียมใจสำหรับ 5% ที่เหลือที่ยอดขายอาจจะดิ่งลงต่ำกว่านั้น [5]
VaR เปรียบเสมือนการกำหนด ‘เกณฑ์ความเสี่ยงสูงสุด’ ในสภาวะการณ์ปกติ แต่มีข้อจำกัดในการอธิบายความรุนแรงที่อาจเกิดขึ้นในส่วนปลายของการแจกแจง (Tail end) ด้วยเหตุนี้ Expected Shortfall (ES) จึงถูกนำมาใช้เพื่อประเมินค่าเฉลี่ยของความเสียหายในกรณีที่เกิดสถานการณ์วิกฤต (Extreme loss scenarios) เพื่อให้องค์กรสามารถบริหารจัดการความเสี่ยงได้อย่างครอบคลุมมากกว่า
9.8 Expected Shortfall (ES): ความสูญเสียในสถานการณ์รุนแรง
ในการวิเคราะห์ความเสี่ยง จุดอ่อนสำคัญของ VaR คือการบอกได้เพียง “ขีดจำกัดของความเสียหาย” ที่อาจเกิดขึ้นภายใต้ระดับความเชื่อมั่นที่กำหนด แต่ไม่ได้อธิบายว่าหากความเสียหายเกินกว่าจุดนั้นแล้ว ความรุนแรงเฉลี่ยจะมากเพียงใด
ES จึงถูกนำมาใช้เพื่อเติมเต็มข้อจำกัดดังกล่าว โดยคำนวณ “ค่าเฉลี่ยของความเสียหายที่เกินกว่า VaR” ซึ่งช่วยสะท้อนระดับความเสี่ยงในกรณีที่เกิดเหตุการณ์รุนแรงหรือสถานการณ์สุดโต่งได้ดียิ่งขึ้น [1]
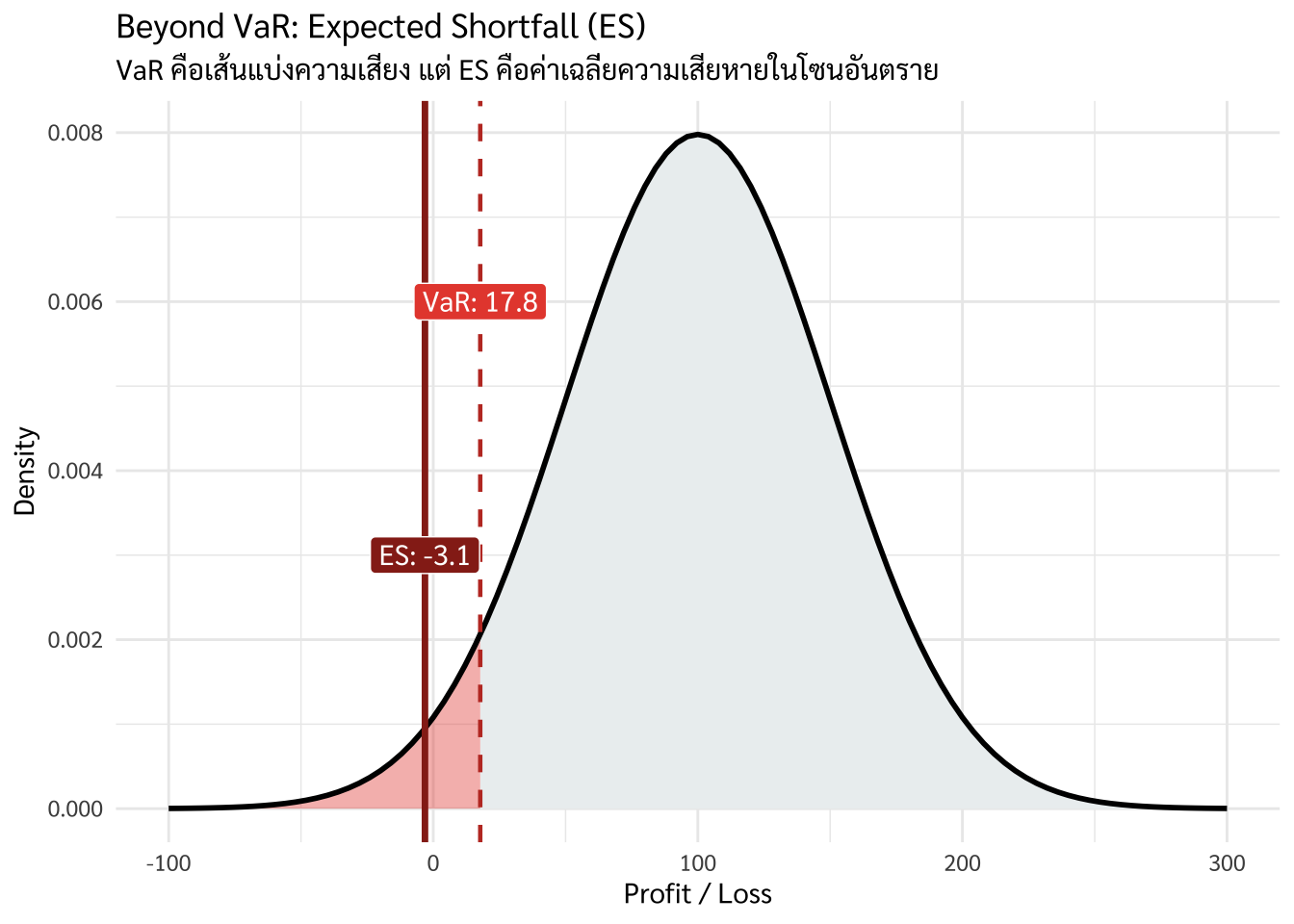
VaR: บอกว่า “เรามีโอกาส 5% ที่จะขาดทุนมากกว่า 1,000 บาท”
ES: บอกว่า “ในกรณีที่เราซวย 5% นั้น โดยเฉลี่ยแล้วเราจะขาดทุนถึง 1,500 บาท”
Risk Coherence: นักศึกษา ES เป็นเครื่องมือที่นักการเงินทั่วโลกยอมรับมากกว่า VaR เพราะมันสะท้อนความจริงของความสูญเสียได้ครอบคลุมกว่า (Coherent Risk Measure)
Decision Making: ถ้าโครงการ A และ B มีค่า VaR เท่ากัน แต่โครงการ A มีค่า ES ที่ติดลบหนักกว่า ในฐานะนักวิเคราะห์ คุณต้องเตือนผู้บริหารว่าโครงการ A มีความเสี่ยงที่จะล้มละลายรุนแรงกว่า (Tail Risk)
The Analyst’s Duty: สถิติไม่ใช่แค่การบวกเลขเฉลี่ย แต่คือการเตรียมความพร้อมให้ธุรกิจรับมือกับสถานการณ์ที่แย่ที่สุดได้อย่างมีสติ
9.9 สรุปสาระสำคัญ
ในบทนี้เราเปลี่ยนบทบาทจากคนเล่าเรื่องด้วยภาพ มาเป็น “นักพิสูจน์หลักฐาน” โดยใช้สถิติเป็นเครื่องมือในการตัดสินใจภายใต้ความไม่แน่นอน ซึ่งมีประเด็นหลัก 3 ส่วน
การหาตัวแทนข้อมูล (Central Tendency): เราใช้ค่าเฉลี่ยเมื่อข้อมูลเป็นระเบียบ ใช้ค่ามัธยฐานเมื่อพยานหลักฐานมีค่ามากหรือน้อยผิดปกติ(Outliers) และใช้ ฐานนิยมเพื่อหาพฤติกรรมกระแสหลัก
การวัดความน่าเชื่อถือและความเสี่ยง (Dispersion & Shape): เราใช้ส่วนเบี่ยวเบนมาตราฐานเป็นไม้บรรทัดวัดความผันผวน และใช้ Histogram เพื่อดู “รูปทรง” ของข้อมูลว่าสมมาตร (Normal) หรือบิดเบี้ยว (Skewed) ซึ่งส่งผลโดยตรงต่อความแม่นยำในการวิเคราะห์
การตัดสินใจเชิงกลยุทธ์ (Risk Analysis):
เราใช้หลักการ Mean-Variance Criteria เพื่อหาจุดสมดุลระหว่างกำไรและความเสี่ยง
พัฒนาไปสู่การวัดความเสียหายสูงสุดด้วยมูลค่าความเสี่ยง (VaR) และการประเมินความเสียหายเฉลี่ยในสภาวะเลวร้ายด้วย Expected Shortfall (ES)
สถิติไม่ใช่แค่การคำนวณตัวเลข แต่คือการเปลี่ยน ‘หลักฐานที่กระจัดกระจาย’ ให้กลายเป็น ‘ข้อสรุปที่ใช้ตัดสินใจได้จริง’ อย่างมีหลักการ
9.10 แบบฝึกหัดท้ายบท
Noteคำชี้แจง
ให้นักศึกษาใช้ข้อมูลจากกรณีศึกษา “Chiang Mai Brew Sales Data” (หรือข้อมูลจำลองที่อาจารย์กำหนด) เพื่อตอบคำถามโดยใช้โปรแกรม Microsoft Excel หรือ jamovi โดยเน้นการตีความหมายเชิงธุรกิจเป็นหลัก
นักศึกษาสามารถ download ข้อมูลจาก
Central Tendency: ให้นักศึกษาคำนวณค่าเฉลี่ย ค่ามัธยฐาน และฐานนิยมของยอดขายต่อบิลใน Excel (ใช้ฟังก์ชัน
=AVERAGE,=MEDIAN,=MODE.SNGL) หากค่าค่าเฉลี่ยสูงกว่าค่ามัธยฐานอย่างเห็นได้ชัด นักศึกษาสรุปได้ว่าข้อมูลชุดนี้มีลักษณะอย่างไร?Dispersion Analysis: จงคำนวณค่าส่วนเบียงเบนมาตราฐานและพิสัยของยอดขาย หากร้านมีค่าส่วนเบียงเบนมาตราฐานของยอดขายเพิ่มขึ้นจากเดือนที่แล้วอย่างมาก สิ่งนี้บอกอะไรกับเจ้าของร้านในแง่ของความเสี่ยง?
Shape of Data: ใน jamovi ให้นักศึกษาใช้เมนู Exploration > Descriptives เพื่อดูค่า Skewness (ความเบ้) หากค่า Skewness เป็นบวก (+) และกราฟ Histogram มีหางลากยาวไปทางขวา นักศึกษาจะแนะนำให้ผู้บริหารใช้ค่าสถิติตัวใดเป็นตัวแทนยอดขายระหว่าง Mean และ Median?
Investment Decision: บริษัทมีโครงการลงทุน 2 โครงการ ดังนี้
- โครงการ A: กำไรเฉลี่ย 100,000 บาท, SD = 10,000 บาท
- โครงการ B: กำไรเฉลี่ย 100,000 บาท, SD = 25,000 บาท ตามหลักการ Mean-Variance Criteria นักศึกษาควรเลือกโครงการใด เพราะเหตุใด?
Dominance Principle: หากโครงการ C มีกำไรเฉลี่ย 120,000 บาท และ SD = 10,000 บาท เมื่อเทียบกับโครงการ A ในข้อ 4 โครงการ C ถือว่า “ดีกว่าในทุกมิติ” (Dominant) หรือไม่? อธิบายตามหลักสถิติ
Value at Risk (Excel): หากยอดขายต่อวันมีการแจกแจงแบบปกติ มี Mean = 5,000 บาท และ SD = 800 บาท จงใช้ฟังก์ชัน
=NORM.INV(0.05, 5000, 800)ใน Excel เพื่อหาค่า VaR ที่ระดับความเชื่อมั่น 95% และอธิบายความหมายของตัวเลขที่ได้Risk Interpretation: จากค่า VaR ที่คำนวณได้ในข้อ 6 หากนักศึกษาต้องรายงานผู้บริหาร “ในสภาวะปกติ เรามั่นใจ 95% ว่ายอดขายจะไม่ต่ำกว่ากี่บาท?” และ “มีโอกาสกี่เปอร์เซ็นต์ที่ยอดขายจะแย่กว่าจุดนั้น?”
Expected Shortfall (Concept): หากค่า Expected Shortfall (ES) ของร้านอยู่ที่ 2,500 บาท ในขณะที่ค่า VaR อยู่ที่ 3,200 บาท (ในกรณีขาดทุน) ตัวเลข ES กำลังบอกอะไรเราเกี่ยวกับ “ความลึกของความซวย” เมื่อเทียบกับ VaR?
Empirical Rule (68-95-99.7): หากยอดซื้อลูกค้ามีการแจกแจงแบบปกติ Mean = 200 บาท, SD = 50 บาท จงคำนวณหาช่วงราคาที่ครอบคลุมลูกค้าประมาณ 95% ของร้าน (ใช้หลักการ \(\pm 2\) SD)
Anomaly Detection: หากพบบิลใบหนึ่งมียอดซื้อ 500 บาท จากข้อมูลในข้อ 9 บิลใบนี้ถือเป็น Outlier หรือ “พยานที่ประหลาด” หรือไม่? (คำใบ้: ตรวจสอบว่าเกิน \(\pm 3\) SD หรือไม่)